AI Model Distillation : how to compress a brain?
Introduction
Large Artificial Intelligence (AI) systems require significant computational power and storage. However, they’re not always practical for everyday use. For example, in applications that demand quick responses or run on less-powerful devices like smartphones or small robots. Thus, we would like to distil these models by making them smaller and faster.
The Essence of Model Distillation
Model distillation is the process of compressing the knowledge of a complex AI model (the teacher) into a more compact and efficient model (the student).
Consider this analogy: You have to study a 1000 pages long textbook for an exam — a daunting task. An expert in the subject offers you a study guide they’ve created. This study guide, perhaps only 100 pages long, includes summaries, simplified explanations, and key points from each chapter. Using this condensed guide is much more manageable. While you might not have the same depth of knowledge, you understand the core concepts well enough to perform on the exam.

Similarly, with model distillation, we have the large model filled with extensive knowledge (the teacher) and a small, new model that needs to learn (the student). The process of model distillation involves the larger model teaching the smaller one to produce similar outputs or results. This is done by running instances through both models and adjusting the student model to mimic the teacher’s outputs.
Benefits of Model Distillation
While we could train a smaller model from the start, distillation has a few benefits. First, larger models are often better at generalising, especially from limited data (source). Thus, a small model trained from scratch may miss out on the insight of the teacher.
Second, we might already have a large model. Thus, we could take advantage of that since training a smaller model through distillation is up to twice as fast. It also requires less than half of the data for optimal results (source).
Third, by transferring knowledge to smaller models, we reduce the need for heavy computing power. We also lower energy consumption when running these models. Model distillation also allows us to shrink the size of the AI model so that it requires less storage space. The smaller model is much easier to handle and can be used in devices with limited storage.
Finally, a smaller model makes decisions (inferences) faster because there are fewer calculations to make. This is crucial for applications where a quick response is important, such as in autonomous driving where decisions must be made in milliseconds.
How Model Distillation Works
Training a large teacher model
First things first we need a teacher. The teacher model is a high-capacity network, meaning it has a large number of parameters (like a big brain). When you train this model, you set high performance expectations. For exemple, you want this AI model to have top-notch accuracy in tasks like image recognition or language processing. Creating this teacher network often involves training it on a large amount of data for a long time (see 1, 2, 3).
Distilling Knowledge
Once the teacher model is fully trained, its knowledge must be distilled and transferred to the smaller, student model. This isn’t about copying the information exactly; it’s more like extracting the essence of the knowledge.
Generally, models provide predictions in the form of labels. Hard labels are definitive answers, like saying, “This is a cat.” Soft labels, on the other hand, show the model’s uncertainty and provide probabilities, such as “There’s a 90% chance this is a cat, a 5% chance it’s a dog, and a 5% it’s something else.” Soft labels are valuable because they contain more information about the teacher model’s thought process. We will use these soft labels to train our students (source).
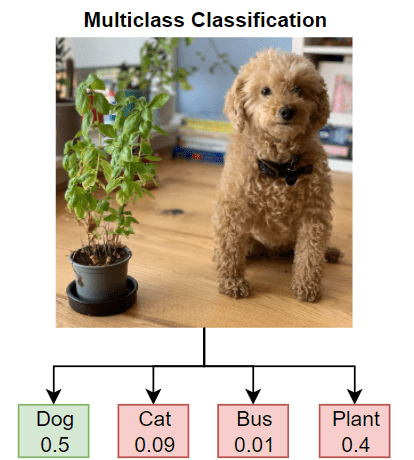
We may also perform what is called Temperature Scaling. This unusual-sounding term is a technique used during the distillation process to soften the probabilities provided by the teacher model. By adjusting the temperature, the model’s certainty is tuned down. Thus, instead of being 99% sure about something, it might only be 90% sure. This “cooler” approach helps when training the student model. It emphasises the important features more subtly and gives the student a gentler learning curve (source).
Training the Student Model
Now comes the part where the lighter, more agile student model comes in, ready to learn from its knowledgeable teacher.
First, the student model’s architecture – its structure and layout – must be carefully considered. It won’t be as complex as the teacher’s, but it must be capable of learning the distilled knowledge. Choosing the right architecture is often a mix of trial and error. We also need to take into consideration the limitations in terms of computing power, memory & speed required by the environment in which the model will be used. A model used in your phone will not have the same consideration as one in your thermostat.
The student model is then trained using the teacher’s soft labels as the training set. Thus, the model is therefore not trained on the basis of the true labels, but on those of the teacher. The more the student model can mimic the teacher’s reasoning, the more the student model learns.
Through these steps we accomplish the goal of model distillation. This allows for the creation of a model that maintains a balance between being lightweight and effective. Thus, it is capable of being used in a variety of real-world applications where agility and efficiency are crucial.
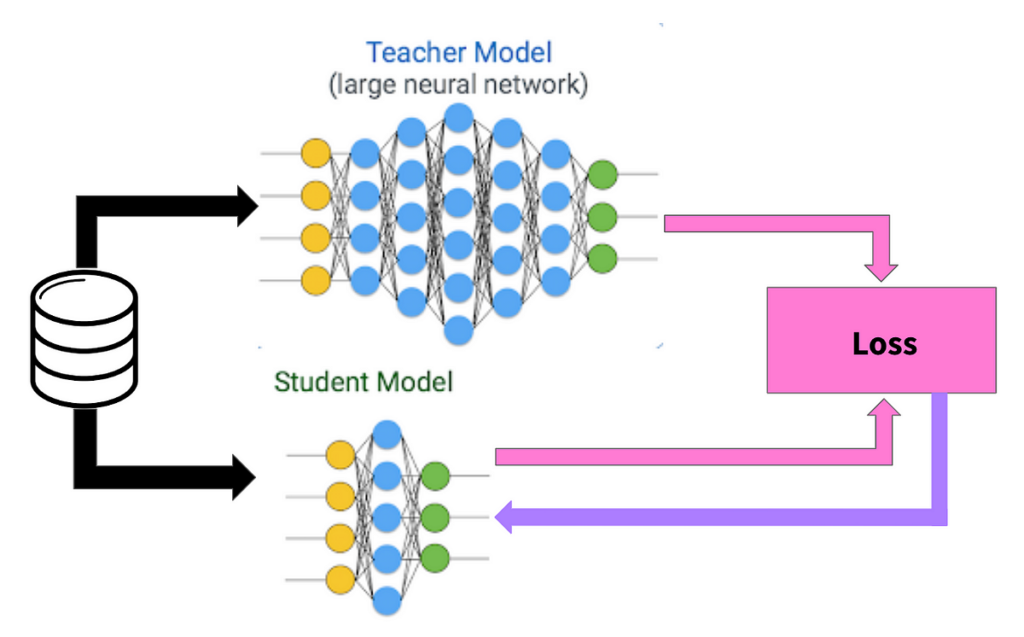
Practical Applications
Model distillation might seem like a high-concept idea. Nonetheless, when you look around, you can see its practical applications everywhere.
Devices, like smartphones and Internet of Things (IoT) sensors, are not always endowed with powerful processing capabilities. Nevertheless, we expect them to perform complex tasks such as voice recognition and image processing. Model distillation enables these small gadgets to have AI capabilities by running simplified versions of large, trained models without compromising much on performance. This is why your phone can recognize your speech or suggest camera settings for a better photo.
This idea is called edge computing; bringing the data processing closer to the source of data, such as security cameras or industrial robots. It allows for quicker response times, as the data doesn’t have to travel back and forth to a central server. Model distillation provides lightweight models that can operate on these edge devices efficiently. For exemple, doing tasks like detecting defects in manufactured products in real-time.
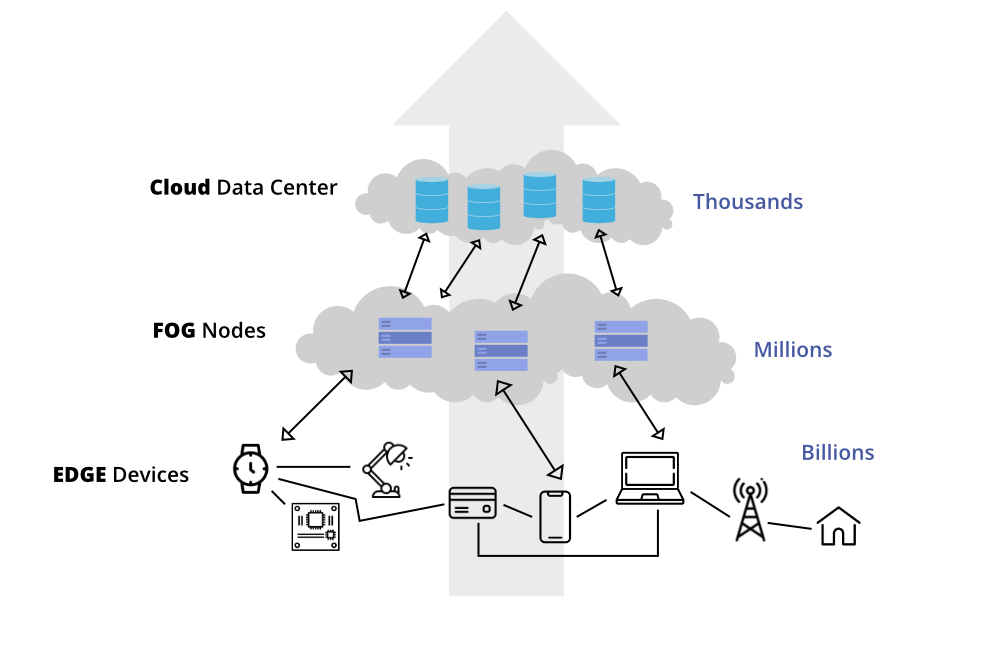
For anything requiring an immediate response, such as automated trading systems or emergency response applications, speedy inference is critical. Distilled models ensure that even though they’re running complex algorithms, they can still make decisions incredibly quickly.
It also helps with privacy : with smaller distilled models, more data can be processed directly on the device. This means sensitive information, like personal health metrics, doesn’t need to leave the user’s device, thus enhancing privacy.
Challenges in Model Distillation
While the idea is to make models smaller and faster, you don’t want to lose the accuracy that the larger model had. Finding the sweet spot where the model is light yet still performs well is a delicate balancing act. Moreover, not all models play well together. Selecting the right teacher and student models is crucial for effective knowledge transfer.
Different AI tasks might require different model architectures, and these don’t always distil in the same way. You may need to customise your distillation approach for the specific type of architecture you’re working with.
It’s not always clear exactly what knowledge the student model has acquired from the teacher. Understanding the nuances of this transferred knowledge is essential for improving and trusting the student model’s decisions (source).
Other Model Distillation Techniques
FitNets: FitNets go a step beyond simply transferring the output of the teacher model to the student model (source). They also focus on transferring intermediate representations – essentially, what the model is ‘thinking’ halfway through its process. This can help a smaller student model learn more complex representations than it would through the final output alone. With this method researchers managed to produce a student that outperforms its teacher.
Born-Again Networks: This approach takes an interesting turn: the student model has the exact same architecture as the teacher model but starts its training afresh (source). The name ‘born again’ comes from the idea that the student model is reborn with the guidance of the teacher model and sometimes can even surpass its teacher in performance. In this case, distillation is not used to compress the model but rather to try and improve it.
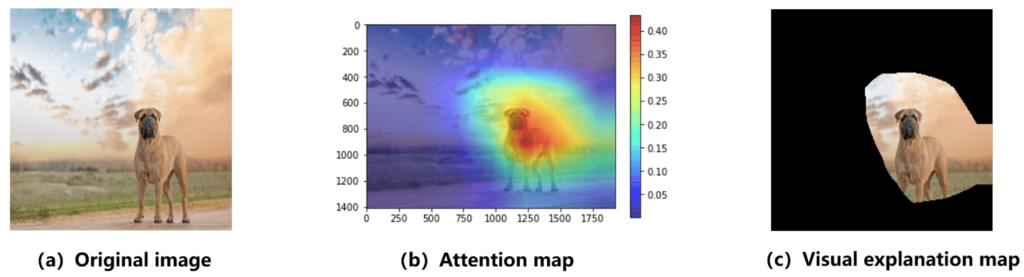
Attention Transfer: Attention transfer borrows from the concept of ‘attention mechanisms’ in neural networks, which highlight what parts of the data are most important for predictions. By teaching the student model where to ‘focus’ its attention, it learns to prioritise the same parts of the data that the teacher model finds important, which can improve its performance (source).
Ensemble teachers: Instead of using only one teacher, we can use a set of teachers and learn from all of them at once (source). For example, by averaging their knowledge when teaching the student.
Conclusion
Distillation holds the key to embedding powerful deep learning models in everyday devices, making them smarter, faster, and more energy-efficient. From your smartphone’s assistant to safety features in cars, distilled models are integral to implementing AI in the real world.
Model distillation is one of the many innovative ways that deep learning is becoming more integrated into our lives. It’s an exciting field where the potential is as broad as the range of devices and applications we use every day.
By making AI models more accessible, model distillation not only pushes the boundaries of what’s possible technologically but also democratically. It allows everyone to benefit from artificial intelligence, regardless of whether they have the latest and most powerful hardware. It’s a pivotal technology that ensures as we move towards an increasingly AI-driven world, we can all join in on the journey.

Is your company looking to integrate AI solutions, analyze data, or strengthen its back-end development? Contact me!
Mail : pro.judicael.poumay@gmail.com
Linkedin : Judicaël Poumay
Portfolio : www.portfolio.thethoughtprocess.xyz
Spinoff project : www.aiashi.be
- Why non linearity matter in Artificial Neural Networks - 18 June 2024
- Is this GPT? Why Detecting AI-Generated Text is a Challenge - 7 May 2024
- The Transformer Revolution: How AI was democratized - 21 February 2024



