La distillation des modèles d’IA : comment compresser un cerveau ?
Introduction
Les grands systèmes d’intelligence artificielle (IA) nécessitent une puissance de calcul et un stockage important. Cependant, ils ne sont pas toujours pratiques pour une utilisation quotidienne. Cela est particulièrement vrai dans les applications qui exigent des réponses rapides ou qui fonctionnent sur des appareils moins puissants. Ainsi, nous aimerions distiller ces modèles en les rendant plus petits et plus rapides tout en maintenant leurs performances aussi élevées que possible.
L’essence de la distillation des modèles
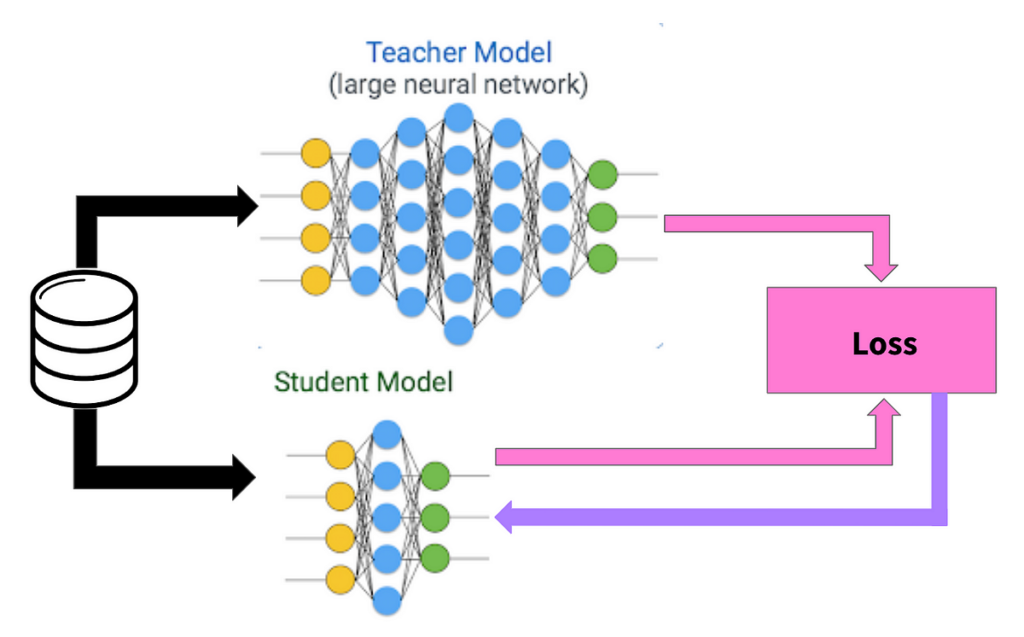
La distillation des modèles est le processus qui consiste à compresser les connaissances d’un modèle. Ainsi on distille un grand modèle (le professeur) dans un modèle plus compact et efficace (l’élève). Le but étant de ne pas perdre l’essence de ce qui a été appris.
Considérez cette analogie : Vous devez étudier un manuel de 1000 pages pour un examen, une tâche intimidante. Un expert dans le sujet vous propose un petit guide d’étude de 100 pages qu’il a créé. Il comprend des résumés, des explications simplifiées et les points clés de chaque chapitre. Utiliser ce guide, bien que condensé, reste suffisant pour bien comprendre les concepts de base pour l’examen.

De même, avec la distillation des modèles, nous avons un grand modèle complexe rempli de connaissances (le professeur) et un petit modèle nouveau qui a besoin d’apprendre (l’élève). Le processus de distillation implique que le modèle plus grand enseigne au plus petit à produire des résultats similaires. Cela se fait en entrainant le modèle élève à imiter les sorties du modèle professeur.
Avantages de la Distillation des Modèles
Bien que nous puissions former un modèle plus petit dès le départ, la distillation présente plusieurs avantages. Premièrement, les modèles plus grands sont souvent plus capable d’apprendre à partir de données limitées (source). Ainsi, un petit modèle formé à partir de zéro pourrait manquer certaines connaissances du modèle professeur.
Deuxièmement, nous pourrions déjà avoir un grand modèle. Nous pourrions donc en profiter car l’entraînement d’un modèle plus petit par distillation est jusqu’à deux fois plus rapide. De plus, cela nécessite moins de la moitié des données pour des résultats optimaux (source).
Troisièmement, grâce à la distillation, nous réduisons le besoin de puissance de calcul et donc la consommation d’énergie lors de l’exécution de ces modèles. Cela nous permet également de réduire la taille du modèle d’IA de sorte qu’il nécessite moins d’espace de stockage. Ainsi, le modèle plus petit est beaucoup plus facile à gérer et peut être utilisé dans des dispositifs à stockage limité.
Enfin, un modèle plus petit prend des décisions (inférences) plus rapidement car il y a moins de calculs à effectuer. Ceci est crucial pour des applications où une réponse rapide est importante, comme dans la conduite autonome où les décisions doivent être prises en millisecondes.
Comment Fonctionne la Distillation des Modèles
Entraînement d’un grand modèle professeur
Tout d’abord, nous avons besoin d’un professeur. Le modèle professeur est un réseau qui possède un grand nombre de paramètres (comme un grand cerveau). Lorsque vous formez ce modèle, vous fixez des attentes de performance élevées. Vous voulez que ce modèle d’IA ait une précision de premier ordre dans des tâches comme la reconnaissance d’images ou le traitement du langage. Créer ce réseau à haute capacité implique souvent de le nourrir avec une grande quantité de données. Il faut aussi le laisser s’entraîner sur ces données pendant longtemps, afin d’afiner ses paramètres pour maximiser la performance possible (voir 1, 2, 3).
Distillation des Connaissances
Une fois entièrement entrainé, le modèle professeur distille et transfère ses connaissances au modèle élève, plus petit. Il ne s’agit pas de copier exactement les informations, mais plutôt d’extraire l’essence des connaissances.
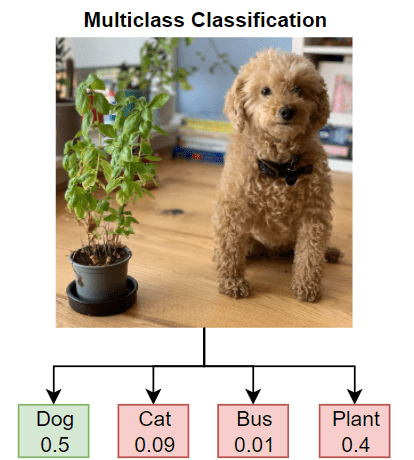
Généralement, les modèles fournissent des prédictions sous forme d’étiquettes. Les étiquettes dures sont des réponses définitives, comme dire : « Ceci est un chat. » Les étiquettes souples, d’autre part, montrent l’incertitude du modèle et fournissent des probabilités. Par exemple : « Il y a 90 % de chances que ce soit un chat, 5 % que ce soit un chien, et 5 % que ce soit autre chose. » Utiliser des étiquettes souples est important car elles contiennent plus d’informations sur le processus de réflexion du modèle professeur. Nous utilisons donc ces étiquettes souples pour former nos modèles élèves (source).
Nous pouvons également effectuer ce qu’on appelle le Calibrage de Température. Ce terme au son inhabituel est une technique utilisée pendant le processus de distillation pour adoucir les probabilités fournies par le modèle professeur. En ajustant la température, on réduit la certitude du modèle. Ainsi, au lieu d’être sûr à 99 % de quelque chose, il pourrait n’être sûr qu’à 90 %. Cette approche aide lors de l’ entraînement du modèle élève. Elle met l’accent sur les caractéristiques importantes de manière plus subtile. Cela offre aussi à l’élève une courbe d’apprentissage plus douce (source).
Entraînement du Modèle Élève
Maintenant, vient le moment où le modèle élève est prêt à apprendre. Tout d’abord, il faut soigneusement envisager l’architecture du modèle élève – sa structure et son agencement. Bien qu’elle ne soit pas aussi complexe que celle du professeur, elle doit pouvoir apprendre les connaissances distillées. Le choix de la bonne architecture implique souvent un mélange d’essais et d’erreurs. Il faut prendre en compte les limitations en termes de puissance de calcul, de mémoire et de vitesse nécessaires dans l’environnement d’utilisation du modèle. Par exemple, un modèle utilisé dans un téléphone n’aura pas les mêmes exigences que celui dans un thermostat.
Le modèle élève est ensuite entrainé en utilisant les étiquettes souples du professeur comme jeu d’entrainement. Le modèle n’est donc pas entrainé sur base des vrais étiquettes mais sur celle du professeur. Plus le modèle élève peut imiter le raisonnement du professeur, plus le modèle élève apprend.
Le modèle final maintient un équilibre entre légèreté et efficacité. Ces caractéristiques se révélant utile dans une variété d’applications réelles où l’agilité et l’efficacité sont cruciales.
Applications Pratiques
La distillation des modèles peut sembler être une idée étrange. Cependant, lorsque vous regardez autour de vous, vous pouvez voir des applications pratiques partout.
Les smartphones et les capteurs de l’Internet des Objets (IoT), ne sont pas toujours très puissants. Néanmoins, nous nous attendons à ce qu’ils effectuent des tâches complexes telles que la reconnaissance vocale et le traitement d’images. La distillation des modèles permet à ces petits gadgets d’executer des versions simplifiées de grands modèles entraînés. C’est pourquoi votre téléphone peut reconnaître votre parole ou suggérer des réglages de caméra pour une meilleure photo.
Cette idée est appelée calcul en périphérie ; elle consiste à rapprocher le traitement des données de la source de données. Par exemple les caméras de sécurité ou les robots industriels. Cela permet des temps de réponse plus rapides, car les données n’ont pas à voyager vers un serveur central. La distillation des modèles fournit des modèles légers qui peuvent fonctionner efficacement sur ces dispositifs en périphérie. Il peuvent effectuer des tâches comme la détection de défauts dans les produits manufacturés en temps réel.
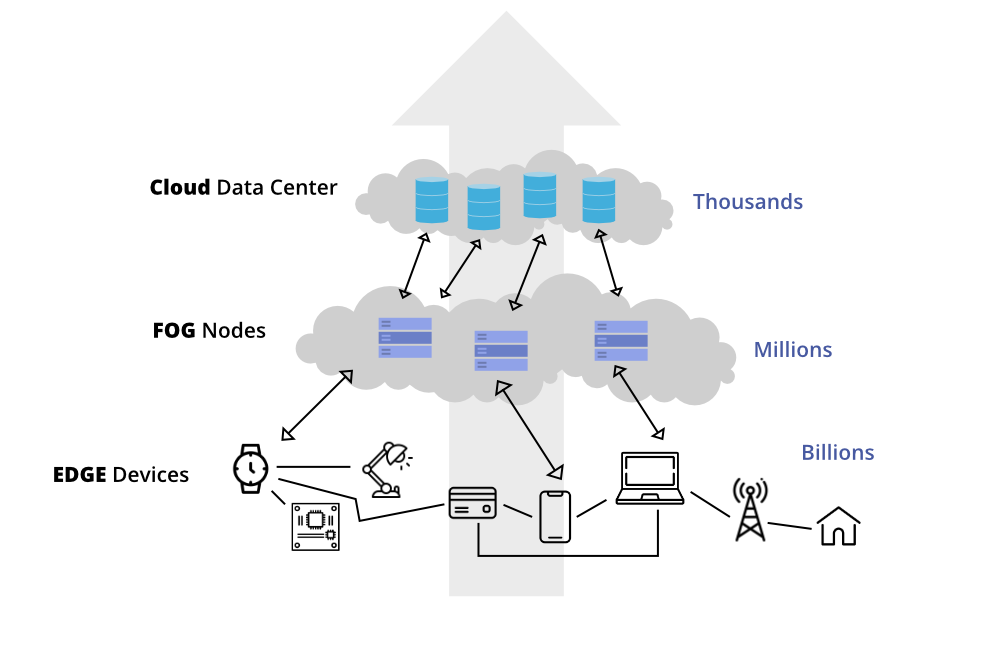
Pour tout ce qui nécessite une réponse immédiate, comme les applications de réponse d’urgence, une inférence rapide est essentielle. Les modèles distillés garantissent que, même s’ils exécutent des algorithmes complexes, ils peuvent toujours prendre des décisions incroyablement rapidement.
Cela aide également à la confidentialité : avec des modèles distillés plus petits, plus de données peuvent être traitées directement sur l’appareil. Ainsi les informations sensibles, comme les données de santé personnelles, n’ont pas besoin de quitter l’appareil de l’utilisateur.
Défis dans la Distillation des Modèles
Bien que l’idée soit de rendre les modèles plus petits et plus rapides, vous ne voulez pas perdre la précision qu’avait le modèle plus grand. Trouver le point d’équilibre où le modèle est léger tout en restant performant est un acte d’équilibrage délicat. De plus, tous les modèles ne s’accordent pas bien ensemble. Choisir les bons modèles professeurs et élèves est crucial pour un transfert de connaissances efficace.
Différentes tâches d’IA pourraient nécessiter différentes architectures de modèles, et celles-ci ne se distillent pas toujours de la même manière. Vous pourriez avoir besoin de personnaliser votre approche de distillation pour le type spécifique d’architecture avec laquelle vous travaillez.
Il n’est pas toujours clair exactement quelle connaissance le modèle élève a acquise du professeur. Comprendre les nuances de cette connaissance transférée est essentiel pour améliorer et faire confiance aux décisions du modèle élève (source).
Autres Techniques de Distillation des Modèles
FitNets : Les FitNets vont un pas au-delà de la distillation de la sortie du modèle professeur (source). Ils se concentrent également sur le transfert des représentations intermédiaires. C’est à dire, ce que le modèle ‘pense’ à mi-chemin de son processus. Cela peut aider un modèle élève plus petit à apprendre des représentations plus complexes. Avec cette méthode, les chercheurs ont réussi à produire un élève qui surpasse son professeur.
Réseaux Renaissants : Ici, le modèle élève a exactement la même architecture que le modèle professeur mais commence son entraînement à partir de zéro (source). Le nom ‘renaissant’ vient de l’idée que le modèle élève renaît avec les conseils du modèle professeur. Parfois, il peut même surpasser son professeur en terme de performance. Dans ce cas, la distillation n’est pas utilisée pour compresser le modèle mais plutôt pour essayer de l’améliorer.
Transfert d’Attention : Le transfert d’attention emprunte au concept de ‘mécanismes d’attention’ dans les réseaux neuronaux. L’attention met en évidence les parties des données les plus importantes. En se basant sur le professeur, le modèle élève apprend où ‘concentrer’ son attention. Par conséquent, il apprend à prioriser les mêmes parties des données que le modèle professeur trouve importantes (source).
Ensemble de Professeurs : Au lieu d’utiliser un seul professeur, nous pouvons utiliser un ensemble de professeurs et apprendre d’eux tous en même temps (source). Par exemple, en moyennant leur connaissance lors de l’enseignement de l’élève.
Conclusion
La distillation détient la clé pour intégrer des modèles puissants dans les appareils de tous les jours. Cela permet de les rendre plus intelligents, plus rapides et plus économes en énergie. De l’assistant de votre smartphone aux fonctionnalités de sécurité dans les voitures, les modèles distillés sont essentiels à la mise en œuvre de l’IA dans le monde réel.
La distillation des modèles est l’une des nombreuses façons innovantes par lesquelles l’apprentissage en profondeur devient plus intégré dans nos vies. C’est un domaine passionnant où le potentiel est aussi vaste que la gamme d’appareils et d’applications que nous utilisons chaque jour.
En rendant les modèles d’IA plus accessibles, la distillation des modèles repousse les limites de ce qui est technologiquement possible. Elle permet aussi à tout le monde de bénéficier de l’intelligence artificielle. Cela indépendamment du fait qu’ils possèdent ou non le matériel le plus récent et le plus puissant. C’est une technologie importante qui assure que le plus de monde possible puissent profiter de l’IA.

Votre entreprise cherche-t-elle à intégrer des solutions d'IA, à analyser des données ou à renforcer son développement back-end ? Contactez-moi !
Mail : pro.judicael.poumay@gmail.com
Linkedin : Judicaël Poumay
Portfolio : www.portfolio.thethoughtprocess.xyz
Spinoff project : www.aiashi.be



