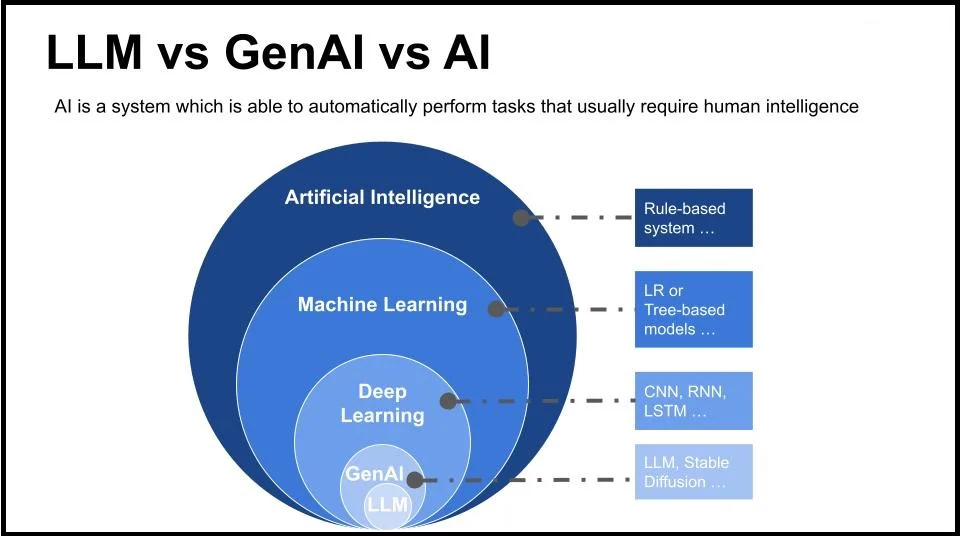
How GPT is Revolutionizing the World of Artificial Intelligence

Introduction
In recent years, the word artificial intelligence and machine learning (ML) became prevalent. This technology has revolutionised how we approach problem-solving across various industries, from healthcare to finance, and even in our daily interactions with technology whether at work or in our personal life.
Recently, with the advent of GPT a new paradigm has appeared : from traditional machine learning models, meticulously crafted and trained for specific tasks, we are now shifting to pretrained models that can be adapted for a multitude of applications through prompt engineering. Understanding these two approaches is key to unlocking their potential in today’s data-driven world.
What is Traditional Machine Learning?
Traditional Machine Learning (ML) is a method where algorithms learn from data to make predictions or decisions. At its core, this process involves six primary steps:
- Data collection, where data is harvested from various sources
- Data pre-processing, where raw data is cleaned and structured
- Data annotation, where data is given labels to be predicted
- Feature engineering, where the most relevant aspects of the data are identified and highlighted
- Model training, where the algorithm learns from this prepared data to make future predictions.
- Model evaluation, where the model is evaluated on new data to validate its performance
For example, if the task involves translating text from English to French, the process would unfold as follows: First, we need to gather a bilingual corpus in both languages. Then we can do some pre-processing, such as removing links. Then, we annotate, which in this case means pairing each English sentence with its corresponding known French translation. After this, we can engage in feature engineering, like encoding the words using word embeddings. Finally, we train the model and evaluate its performance.
The strength of traditional machine learning lies in its specificity. Models are tailor-made for the task at hand, whether it’s predicting stock market trends or diagnosing diseases from medical images. This customization requires a deep understanding of both the problem and the data, necessitating significant investment in data collection and processing, as well as model development and tuning.
What is Prompt Engineering with Pretrained Models
Pretraining is a specific ML approach that has emerged with the rise of large of models like GPT-3, BERT, and others. These models have been trained on vast datasets, encompassing a wide range of knowledge and linguistic structures. Instead of building a model from scratch as in the traditional approach, we can use pre-trained models that then act as a knowledge base on which prompt engineering can be performed.
Prompt engineering involves crafting inputs (prompts) to these pretrained models in a way that guides them to produce the desired output. Thus, the model training step is replaced by prompt tuning where the difficulty lies not in tuning hyperparameters or costly training computation but rather meticulously defining the input prompt with the right exemples, context and directives. This task requires a deep knowledge of the inner workings of the pre-trained model and the problem to be solved to ensure that the exemples used in the prompt are as representative and diversified as possible to represent the closest possible to the real distribution of the input-output pairs that define the problem.
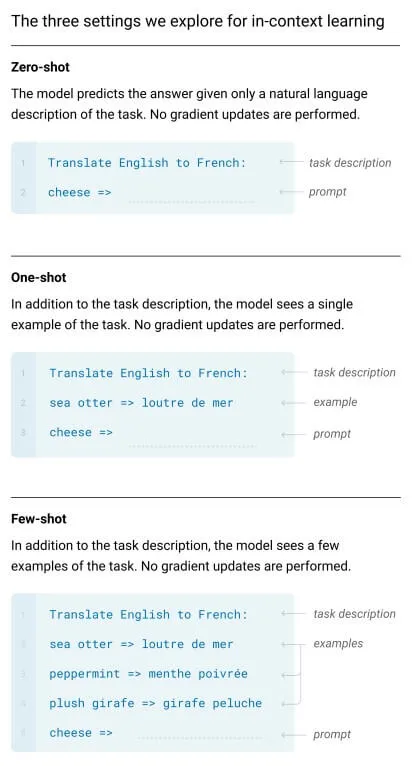
In this case, the task of translating text from English to French is much simpler to accomplish. All we need to do is equip ourselves with a pre-trained model such as GPT-4 and provide it with a prompt. This prompt contains the definition of the task, a few example sentences along with their translations, and finally the current sentence to be translated, as can be seen in the image above. And that’s all! GPT-4, having already been pre-trained on a huge corpus, has already learned the concept of translation; it just needs to be asked correctly with a prompt.
This approach leverages the extensive learning these models have already undergone, making it possible to apply them to a variety of tasks without the need for extensive dataset curation or model training specific to each task; we call this transfer learning. From generating creative content to answering complex queries, the versatility of prompt engineering with pretrained models is shocking.
Through this approach, the burden of data collection, preprocessing, and annotation is greatly reduced and, in some cases, eliminated. This aspect is crucial to acknowledge, as these steps typically constitute a significant portion of the modelling task in terms of time and cost. The use of pretrained models substantially alleviates these demands, streamlining the process of deploying machine learning solutions.
Pros and Cons
Traditional Machine Learning
Pros : Traditional machine learning is highly Customizable as it can be tailored to specific tasks with a high degree of precision. Moreover, we collect and preprocess the data ourselves which brings more control and validation over what the model ingested.
Cons: However, training a model is a resource-intensive process that requires significant investments. Data collection, preprocessing and annotation is costly and generally accounts for the majority of the time taken in ML projects. Moreover, training a model can also be extremely costly as well as time consuming.
Prompt Engineering on Pretrained Models
Pros: Prompt Engineering on Pretrained Models limits the need to deal with data which lead to cheaper and faster model deployment. It also means that such models can quickly adapt to changes in the problem specification.
Cons: The main problem with pretrained models is that we have little oversight on the data sources and preprocessing methods used for its creation. Thus, for sensitive tasks such as medical or financial problems, such models may not be appropriate. Nonetheless, we can also use pretrained models on medical or financial data to alleviate this issue.
Conclusion
In the futur, Prompt Engineering on Pretrained Models could become a ubiquitous in industrial applications considering its speed of deployment and reduced cost. We might witness the emergence of more sophisticated prompt engineering techniques, making pretrained models even more versatile. Simultaneously, traditional machine learning will continue to advance, especially in areas requiring extreme precision and data oversight.
In conclusion, both traditional machine learning and prompt engineering with pretrained models offer unique advantages and drawbacks. The choice between them should is guided by the specific requirements of the task at hand, considering factors like data availability, the need for customization, and resource constraints. As the field evolves, the synergy of these two approaches may pave the way for more innovative and efficient solutions in the realm of artificial intelligence.



