Introduction
Artificial intelligence (AI) has seen important advances over the past decade. More specifically, the field has been marked by the democratization of large language models (LLMs) with the release of ChatGPT. Although LLMs do not represent the entirety of the AI field, they constitute the most impressive part of it to date. Let’s explore this history together to understand how we got here.
1950-2012: Prehistory & the harsh winters
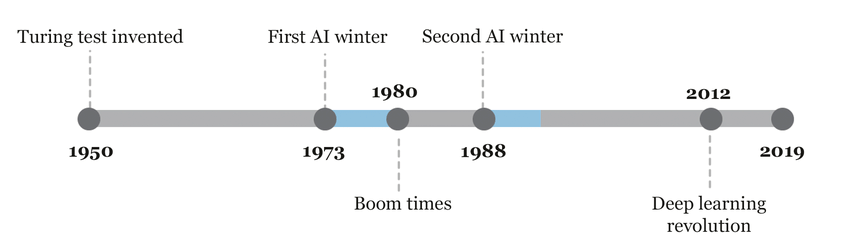
If we were to start from the beginning of the history of AI we would have to start in the 1950’s. I already have an article discussing the complicated early history of AI so we won’t spend much time here. In brief, this was a difficult time for AI researchers, while they had good ideas they did not have the computing power, data or tools necessary to appreciate the full power of their theories. This led to two so-called “AI winters” 1973-1980 and 1988-1993, times where optimism about AI was low and funding even lower.
Nonetheless, a lot of important work was done between 1950 and 2012 this include the invention of the first neural network (1958), the basic training procedure for neural network known as backpropagation (1974) and many important neural architecture (MLP 1986, RNN 1986, LSTM 1997).
However, it’s this last decade that saw the greatest discoveries in the field of AI with the advent of LLM such as GPT. Thus, let’s review the evolution of AI since its resurgence in 2012. More specifically which discoveries were key in the making of current LLM technology.
2012: AlexNet, the rise of neural network
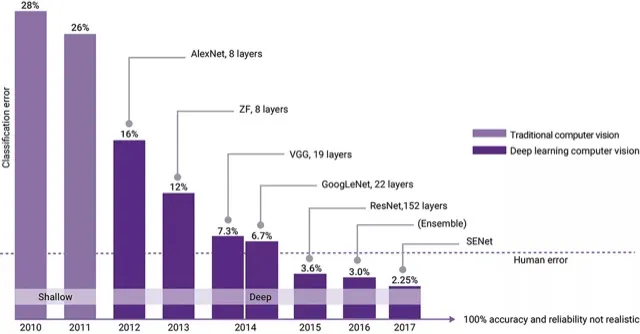
In 2012, AlexNet revolutionized the field of deep learning. Although neural networks date back to the 1950s, they had seen little success until 2012. AlexNet’s performance rekindled interest in neural networks.
AlexNet is not a particularly new model, but it was able to take advantage of the computing power and data access of its time. This allowed it to demonstrate to the world that this type of model could outperform traditional methods in complex tasks. Its success encouraged further research in deep learning, paving the way for more sophisticated models in various fields, including natural language processing (NLP). For this reason, AlexNet is one of the most important models in the AI community; it is the model that ushered in the modern era of AI, also marking the beginning of the big data and deep learning era.
2013: word2vec, when computers started to understand words
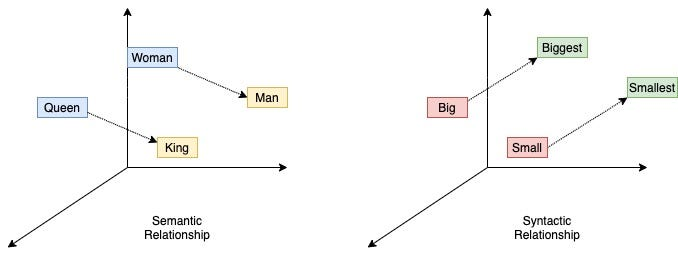
Since AlexNet, researchers learned that neural networks were a viable technology. However, using these models for text analysis remained complicated. This quickly changed with the introduction of word2vec in 2013, which marked an important milestone in natural language processing (NLP), a field where AI is applied to analyze texts. The release of Word2Vev was the day computers learned to understand words.
More specifically, word2vec is a neural network-based technique that transforms words into numerical representations while capturing the semantic relationships between them. Thus, using the Word2Vec representation, the following formula is true: KING-MAN+WOMAN=QUEEN. By linking mathematics and linguistics, this allowed researchers to perform algebra on words and thus to analyze documents using AI models. This was the beginning of neural NLP.
2016: fastText, breaking words into pieces

In 2016, Facebook’s AI Research team introduced fastText, an improvement on word embeddings solutions such as word2vec. FastText extended the word2vec model by incorporating subword information, enabling it to handle rare and out-of-vocabulary words more effectively. Specifically, fastext creates representations for parts of a word. For example, “unexpected” could be split into “un” and “expected”, both elements of the word can be studied separately providing a more powerful representation of the whole word. This approach allowed fastText to produce more accurate and robust embeddings, particularly for morphologically rich languages.
These last two innovations are commonly referred to as static word embedding, they represent methods of encoding words into numerical spaces for easy computation by AI systems. Many other static embeddings were proposed during this time. However, this kind of embedding have one limitation : polysemy or “multiple meaning”. For example, words like “bass” can represent a fish or an instrument depending on the context. These static embedding only produced one representation for each word thus ignoring the context in which they are used and thus a lot of information.
2017: Reading well requires attention
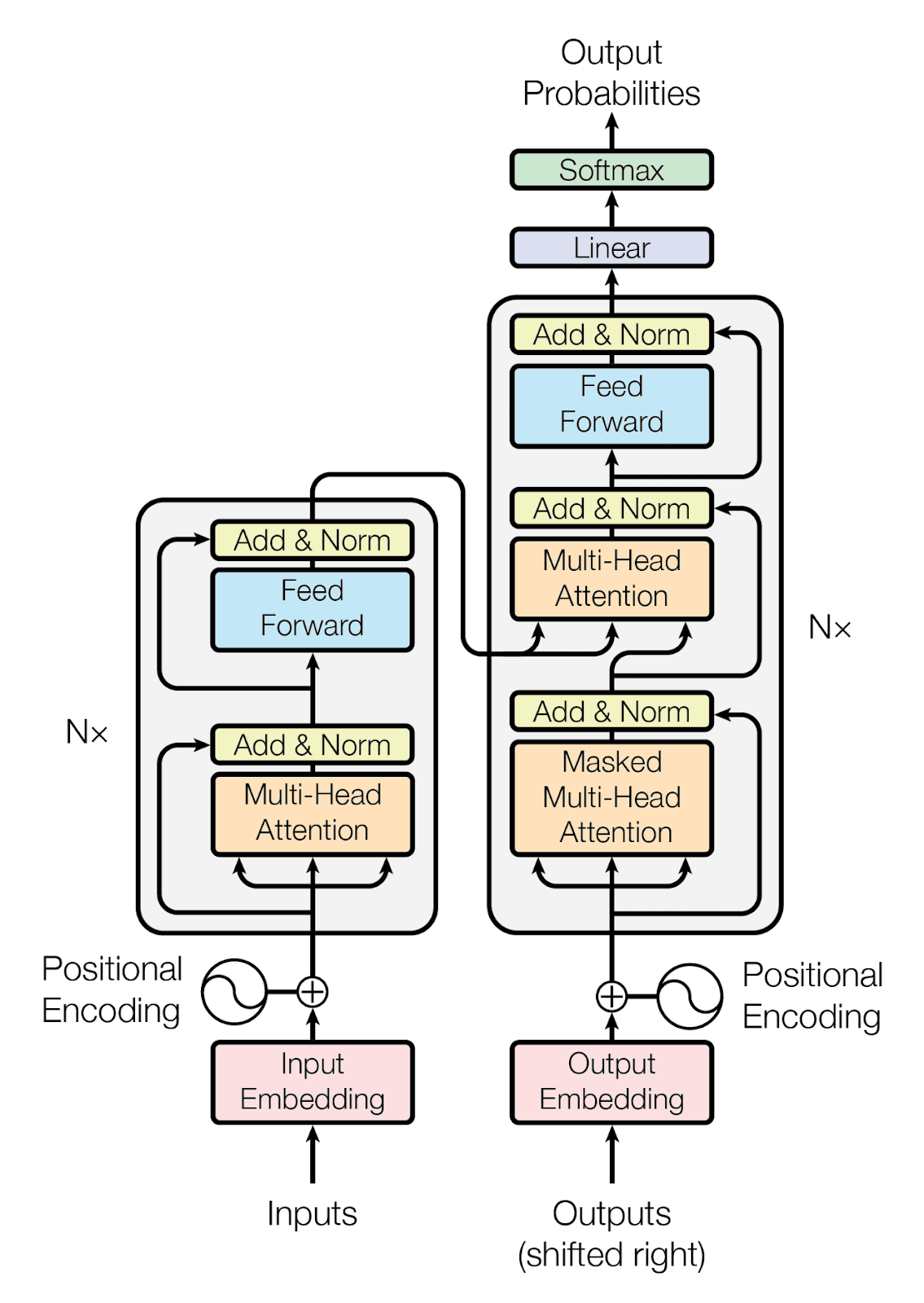
The groundbreaking article “Attention is All You Need” introduced a new way of processing language with computers: the Transformer architecture. Before this, the models used to understand and generate text had limitations, especially when it came to understanding long and complex sentences. The Transformer, with its self-attention mechanism, overcame these challenges by allowing the model to learn how to read.
This advancement not only sped up the training of models but also enabled the creation of much larger and more powerful models. It paved the way for significant progress in machine understanding and text generation.
The concept of attention also allowed for better handling of polysemy. Models can thus adapt the representation of words based on their use in the sentence.
The power and flexibility of the attention concept mark another key step in the evolution of the AI field. This concept also marks the beginning of large language models and the modern revolution of AI and natural language processing (NLP).
2018: GPT, writing one word at a time
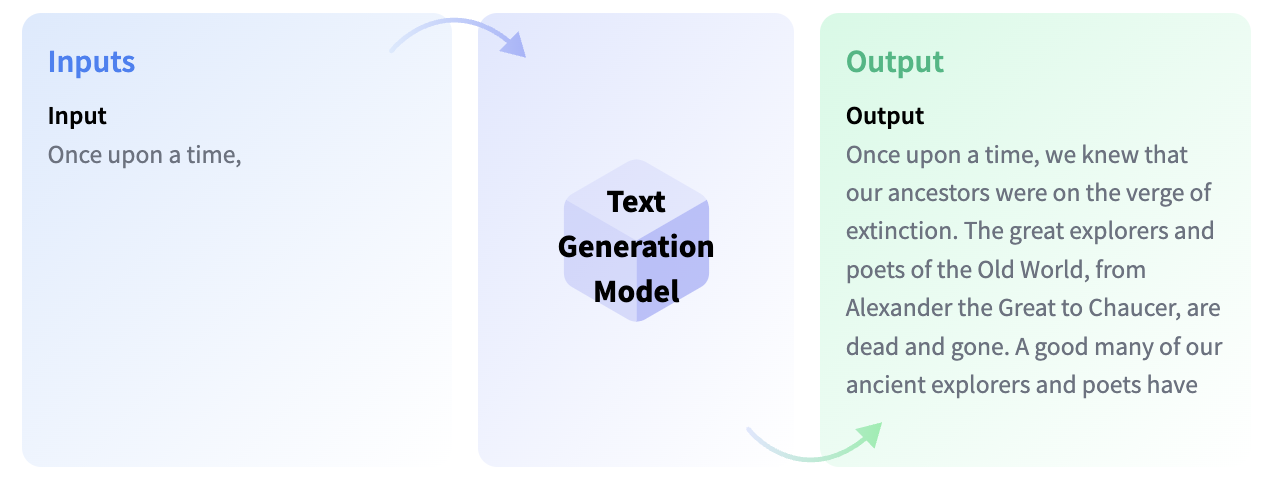
In 2018, OpenAI introduced GPT. Unlike other models, which were trained to complete missing words in sentences in order to generate embeddings, GPT was trained to generate the next token in a sequence, giving it the ability to generate text. This innovation led to more powerful and sophisticated versions in the GPT series. While still producing contextualised embedding at its core, its main job is now to generate text instead. Nonetheless, this early version produced text that was incoherent although grammatically correct. Now AI is starting to learn how to write.
2020 & 2022 : GPT-3 & ChatGPT, the democratization of AI

GPT-3, released by OpenAI in 2020, represented a monumental leap in AI capabilities. With 175 billion parameters, GPT-3 was the largest and most powerful language model of its time. Its sheer size and scale allowed it to perform a wide array of tasks with minimal fine-tuning, from answering questions to generating code. GPT-3’s versatility and performance demonstrated the potential of LLMs to transform industries and redefine human-computer interactions. It was this model that became the public face of AI in 2022 with the release of ChatGPT. This forever changed the field of AI from a mostly academic enterprise to a household name.
2024: Current Models
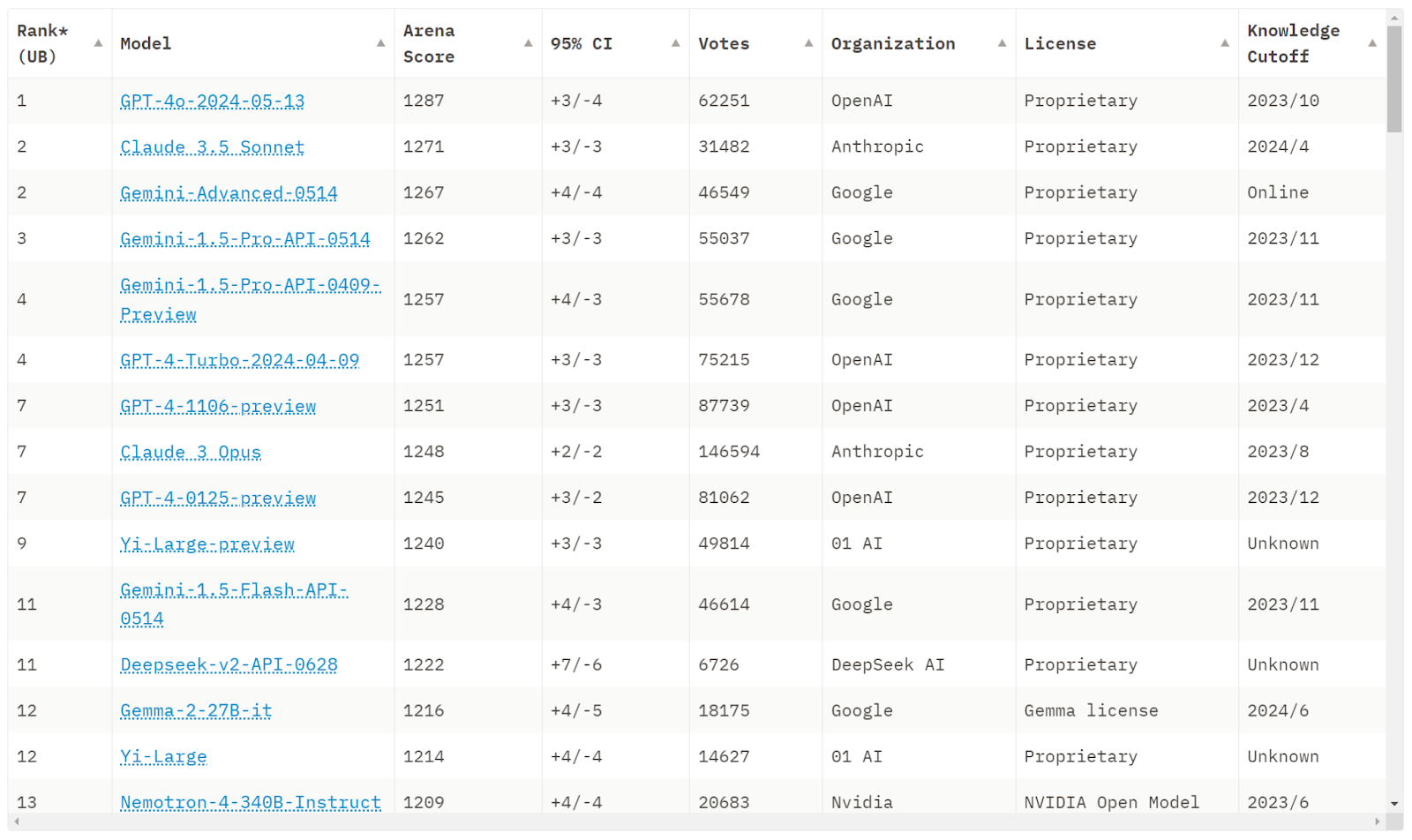
As of 2024, the landscape of AI and language models has continued to evolve rapidly. Current models such as GPT-4, LLama, Claude, Gemini, Mistral, Palm, Falcon, and Grok represent the cutting edge of NLP technology. While each model differs slightly, they all share the same underlying technology that we have showcased thus far. Nonetheless, the latest Open AI model (GPT4o) models remains the best performing model overall as we can see in this leaderboard : https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard.
Conclusion
The rise of AI from AlexNet to the latest LLM giants reflects the tremendous progress in AI and NLP over the past decade. Each innovation has built upon the previous breakthroughs, contributing to the sophisticated models we see today. As AI continues to advance, these language models will undoubtedly play a pivotal role in shaping the future of technology, transforming the way we interact with machines.

As an independent AI researcher/developer specialized in Natural Language Processing (NLP), I have a comprehensive expertise in the development and integration of AI systems, as well as data analysis.
Is your company looking to integrate AI solutions, analyze data, or strengthen its back-end development? Contact me!
Mail : pro.judicael.poumay@gmail.com
Linkedin : Judicaël Poumay
Portfolio : www.judicael-poumay.be
- Attention Mechanism in LLM Explained : A Deep Dive - 27 May 2025
- Tokenization in LLMs: Why Not Use Words? - 6 March 2025
- Defining AGI : Why OpenAI’s o3 Isn’t Enough to achieve Artificial General Intelligence - 26 December 2024