Reading notes #6 : Language models

Natural Language Processing (NLP) is the study of human languages through Artificial Intelligence. It aims to understand the inner workings behind languages to automate language-related tasks such as automatic translation, text-to-speech, speech recognition, opinion mining, and many more.
However, to perform those tasks, we need to teach computers to have a good understanding of languages. This includes understanding grammar, syntax, vocabulary, context, structure, and punctuations. Moreover, words have a disadvantage in that they are made of letters. However, letters on their own have no meaning, and computers can only manipulate numbers.
Hence, NLP practitioners rely on language models (LM) to solve all of these issues. Language modeling refers to the task of predicting words given a context. For example, given the context “The … meows loudly”, the model should predict that “…“ is “cat”. By training LMs on millions of documents, these models end up understanding how words are related to each other. In doing so, these systems also learn to represent words as vectors of numbers. Such representations can then be used to manipulate text using computers and solve most NLP tasks.
Hence, LMs are one of the most studied sub-field of NLP, and consequently, there are many scientific papers on the subject. In this article, I will present some of these articles that caught my eyes recently.
Reading notes
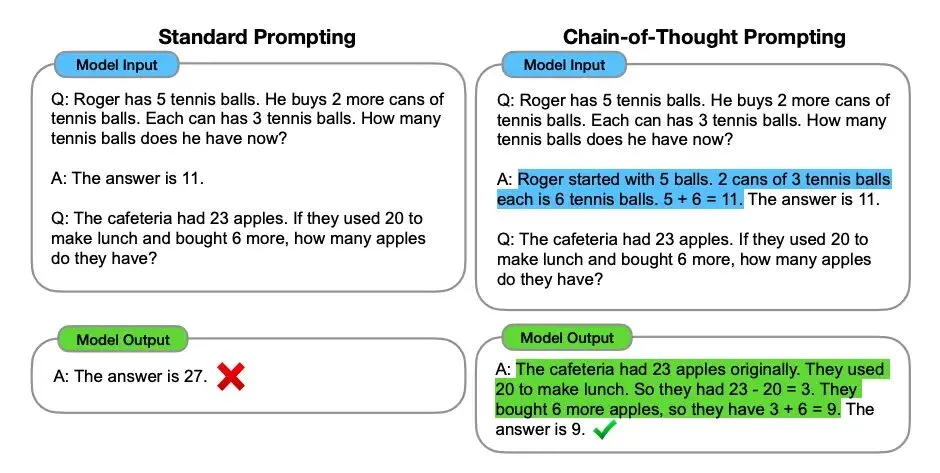
Chain of Thought Prompting Elicits Reasoning in Large Language Models
This paper presents a method for improving the logical reasoning of language models. They propose to train the models to produce chains of thought. This means that the model is taught to provide a logical argument that leads to their answer instead of directly output what it thinks the answer is. The author of this article has shown that forcing the model to provide reasoning for their answer improves their performance.
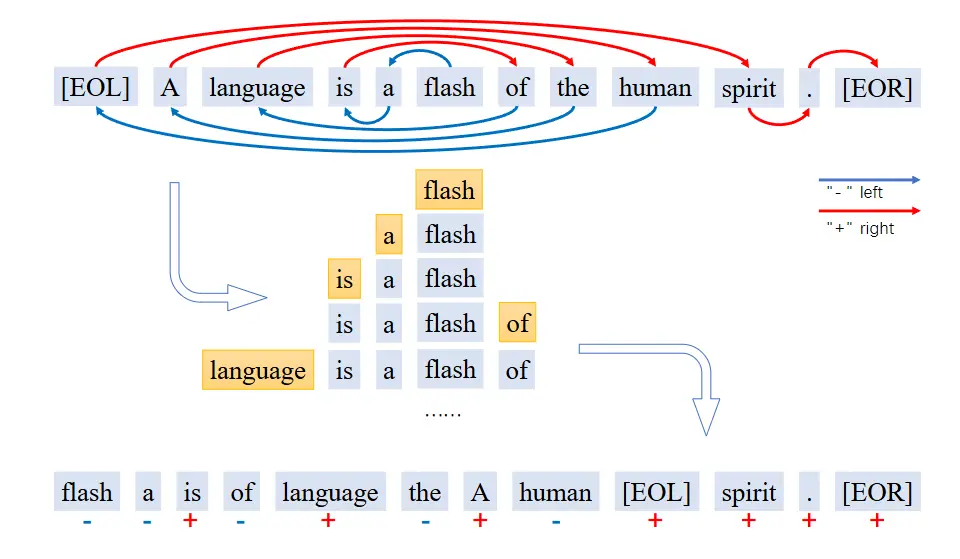
Traditional text generation techniques using LMs rely on an initial word or phrase to generate text from left to right or vice versa. In this paper, the authors propose to start from an initial word and generate text around it without a specific direction. Hence, text can be generated after and before the initial word. This provides more flexibility in generating text and better performance in some tasks than traditional techniques.
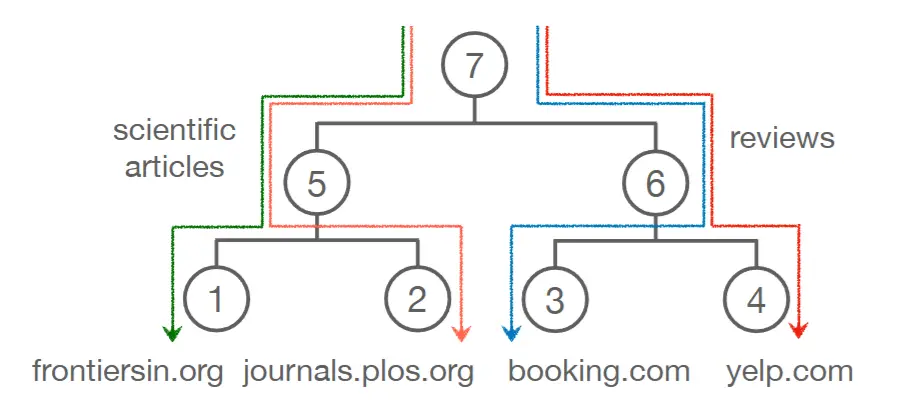
Efficient Hierarchical Domain Adaptation for Pretrained Language Models
This paper proposes a system to train LMs to specialize in many domains simultaneously. They structure domains in a hierarchy using a tree and then assign an adapter to each node. Each time the LM is used, a sequence of adapters is applied corresponding to the path to the domain node. Each adapter will modify the model’s behavior to be consistent with the requested domain. They show such a method yield better results and are also less computationally expensive as the hierarchical structure allows for sharing of parameters between ancestor & child domains. Moreover, this also helps low resource domains by tying them to their higher resource ancestor domain.
How Language-Neutral is Multilingual BERT?
In this paper, the author investigates the multilingual model mBERT. They show that mBERT inner representations can be split into language-specific and language-neutral components. This demonstrates the existence of a mathematical commonality between all of the human languages studied.
Boosting coherence of language models
In this paper, the authors discuss the fact that language models (GPT in particular) tend to put too much emphasis on recent context. Consequently, such models perform more poorly with question answering (QA) tasks as they tend to forget past information easily. Thus, the author proposed an ensemble solution using two language models, one using the whole context and one using a smaller context. Thus we have one model that focuses on local information and the other on more global information. To produce a result, their solution is weighted. This technique leads to better QA performance.

What do Compressed Large Language Models Forget? Robustness Challenges in Model Compression
This paper asks the interesting question of what kind of impact compression has on LMs regarding robustness, generalization, and bias. They investigate two popular compression methods: knowledge distillation (teacher/student paradigm) and pruning. They show that compressed models perform worse on adversarial test sets while still performing similarly on the in-distribution dataset. Hence, compressed models seem to overfit more and be overly confident. They are also more biassed. The authors also propose a method to improve the robustness of compressed models.
Temporal Attention for Language Models
Language models learn the semantic relationship between words. However, the meaning of words can change over time. Hence, the author of this paper proposes to integrate temporality in LMs. They have shown that this significantly increases the model’s performance, especially for semantic change analysis.
Interpreting Language Models with Contrastive Explanations
This paper focuses on interpreting LMs reasoning. They propose to use contrastive explanations by asking why the model chose X instead of Y. Using attention, they can pinpoint which words in the input affected the output the most. Thus, providing a clearer view of the inner workings of an LM. Their approach provides an interesting way of studying LM.

Language Models are not Models of Language
This paper makes the claim that language models should be called corpus models instead. Indeed, LMs are trained over a corpus of text; therefore, their understanding of language is limited by the corpus they were trained on. Thus, the authors argue against the claim that language models model language. For them, they are instead stochastic parrots incapable of generating innovative ideas. This article is part of a larger debate between Saussure and Chomsky. One believes that language can be reduced to a mathematical model, while the other believes language reflects an empirical reality that cannot be reduced into simple mathematical rules.



