In my last article, I briefly presented neural networks and how they make decisions. But the topic is obviously quite complex and I used a basic network as an example. In this second article in my neural network series, I will show off the main types of network architectures that exist. The goal is not for you to understand but to hopefully marvel at the beauty of some of these concepts.
Feed-forward neural network
The simplest form of neural networks I presented in the last article is called feed-forward neural networks (or sometimes multilayer perceptron). This type of network takes in numbers and returns other numbers. I explained their inner workings in this article.
These networks can solve a large set of problems, but this flexibility makes them heavy. This means more memory usage and more training time. Indeed, these networks tend to be made up of many more parameters than other architectures.
Convolution neural networks
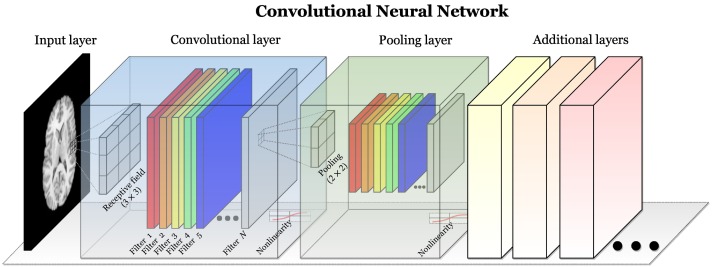
Enter convolutional neural networks (CNNs). These kinds of networks are designed to deal with images. To achieve this, CNNs take advantage of image structure : closer pixels are more related. This relation between pixels is captured through the use of so-called convolutional and pooling layers. This assumption on the input structure greatly reduces the number of parameters the network has to learn, making it easier to train and lighter in memory.
Convolutional layers model the relation between close pixels and pooling layers reduce the image size. Pooling essentially reduces the distance in pixels between objects in the image. Hence, each pooling operation allows the next convolution operation to look further away. Today, CNNs are used for tasks such as facial recognition, self-driving cars, medical diagnostics, and much more.
Recurrent neural networks
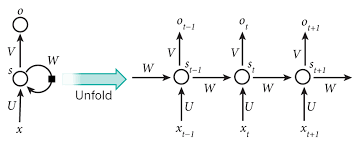
If you want to deal with sequence data (sound or text), you can use recurrent neural networks (RNNs). These networks adopt another constraint : the data is sequential, meaning each element is affected by the one before it. RNNs can handle input of undefined size which is not the case for most other architectures. In RNNs, the input is not fed all at once, but element by element, the network remembers past elements to make present decisions.
The problem is that RNNs have short-lived memory. This is the consequence of how the math works. To alleviate this, an improved version of RNNs was invented : LSTMs (Long-short-term memory). LSTMs manage their memory in a separate state and learn when to remember and when to forget. A further improvement came in the form of bidirectional LSTMs or Bi-LSTMs, which uses two LSTMs that run in both directions. Classic LSTMs and RNNs only look backward while BiLSTMs also look forward.
These kinds of neural networks are used in a variety of ways. When dealing with textual data, they can translate between languages and engage in conversation. When dealing with sound they can create human voices or music.
System of networks
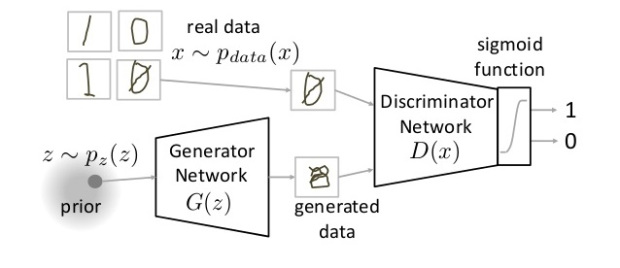
Generative adversarial neural networks (GANs) are systems of two competing networks. The generator is tasked to produce believable data e.g. human faces and the discriminator is trained to differentiate true images from the one produced by the first network.
Thus, the first network tries to fool the second and the second tries to outsmart the first. This competition drives the learning process and the results are amazing. We use GAN when we wish to generate artificial data such as images, voice and text, but they can also be used for other purposes.
GANs are only one form of neural systems. There are many other architectures where two or more networks work in cooperation or competition to learn to solve a task. These neural systems provide incredible possibilities in how to craft interactions between networks.
Other kinds of networks
Transformers are the new revolutionary architecture that is competing with (Bi-)LSTMs and CNNs. Transformers networks make use of the so-called attention mechanism; they learn where they need to pay attention in an image, sound or text in order to make a decision. Open AI recently released GPT-3, a transformer with 175 billion parameters that took about 4 million $ to train. It was fed 40+ TB of english text data and learned ,without supervision, grammar, syntax, spelling, semantic relationship between words and much more.
Auto-encoders are another impressive type of neural networks. Their defining characteristic is that they are shaped like an hourglass, thinner in the middle than in the extremities. They are trained to output exactly what was inputted. This may seem useless but is actually extremely important. As the high dimensional data is forced to pass through a lower dimension space to come out the other end, the network learns to compress the data efficiently.
Hence, these networks can learn to compress data into fewer dimensions with little loss in quality. The downside is that if you give one of these network data it has never seen, it will do a much poorer job. But if one wishes to compress a movie, for example, these can definitely compress it much better than any other compression algorithm. This is because they are constrained to learn to compress this movie and not any other which leads to a much better compression. Netflix uses them to improve video quality for slow internet connection.

In this article I have briefly described to you the most important types of architectures used in neural networks. Each has been developed to deal with a specific type of data, task or to improve on previous architecture. I hope this peak into the world of the neural network was interesting. This technology is truly amazing and will revolutionize the world in a way we still can’t understand.

As an independent AI researcher/developer specialized in Natural Language Processing (NLP), I have a comprehensive expertise in the development and integration of AI systems, as well as data analysis.
Is your company looking to integrate AI solutions, analyze data, or strengthen its back-end development? Contact me!
Mail : pro.judicael.poumay@gmail.com
Linkedin : Judicaël Poumay
Portfolio : www.judicael-poumay.be
- How RLHF works for LLMs : A Deep Dive - 1 July 2025
- Attention Mechanism in LLM Explained : A Deep Dive - 27 May 2025
- Tokenization in LLMs: Why Not Use Words? - 6 March 2025