In recent years, the world of Artificial Intelligence has seen a democratic revolution; everyone has heard about it. This is largely due to a groundbreaking architecture known as Transformers. this advancement paved the way for machines to understand and generate human language in ways previously unimaginable. In this article, I will describe the technological advancements that have enabled such a change.
GPT, what is that?
Imagine having a conversation with a machine that can predict what you’re about to say next. That’s GPT in a nutshell – a language model designed to predict the next word in a sequence. Actually it’s all it does and nothing more. It looks at past words, sentences and paragraphs and then decides what words to produce one by one. Yet, it is capable of producing extremely accurate answers to most questions you ask it. Its intelligence stems from analyzing vast amounts of text data and understanding language nuances. Basically, it has read the entirety of the internet and acquired the combined knowledge of humanity.
Then, what’s a Transformer?
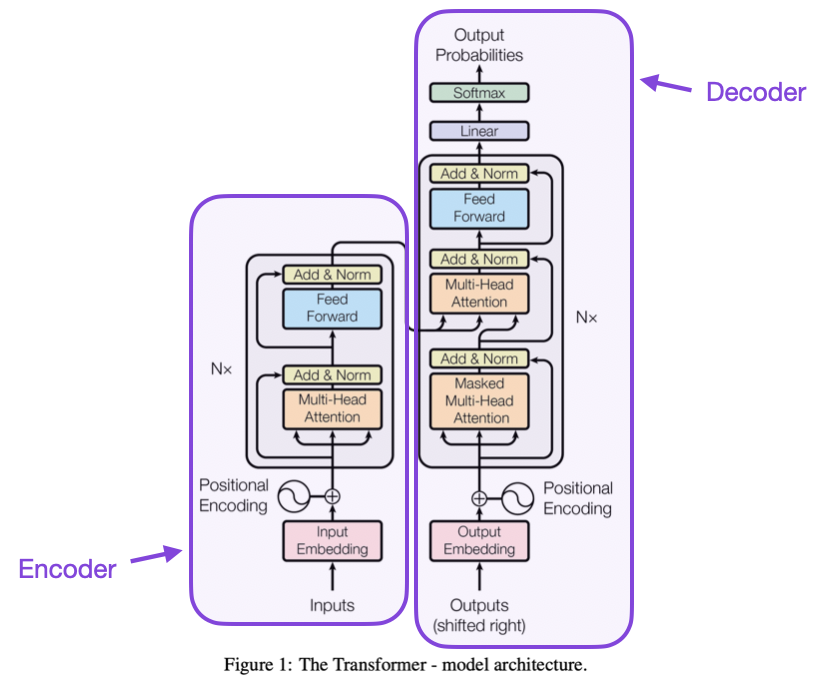
The Transformer Architecture is the brain behind GPT (Generative Pre-trained Transformer). It is a neural network architecture tailored for NLP tasks. Unlike its predecessors, it excels at processing sequences of text, such as translating languages, summarizing articles, or generating human-like responses.
At its core, a Transformer takes a sequence of input words (like a sentence or a paragraph) and transforms it into a new sequence of words. This transformation process involves understanding the context of each word, its relationship with other words, and the overall intent of the text. For instance, imaging translating a sentence from English to French. The Transformer doesn’t merely translate word for word. It considers the entire sentence’s context to choose the most appropriate words in French. Similarly, in text summarization, the Transformer identifies key points and themes in a paragraph and rephrases them succinctly. The Transformer’s ability to generate coherent and contextually relevant text makes it an invaluable tool in creating chatbots, generating creative content, and even assisting in writing code. It’s like having a highly skilled linguist and writer who can quickly grasp the meaning of texts and translate or summarize them accurately in seconds.
Why is it revolutionary?
Transformers have revolutionized AI by introducing a series of innovations that address the critical limitations of previous models’ methods. Let’s examine in detail what and why.
Overcoming the Long-Term Dependency Challenge
As the distance between words increases, previous models found it increasingly difficult to maintain the connection between them. This is due to the sequential nature of their processing, which limits their ability to remember context over long sequences. Transformers does not read words left to right but takes a whole text at once. They discover interactions between every word no matter the distance. This means that in a complex sentence, the Transformer can easily relate a word at the beginning of a paragraphe to another word much later in the sequence. This ensures a deep understanding of the context and nuances of the language.
Parallel Processing Capabilities
This ability of reading a bunch of text at once and not sequentially, means transformers are much faster than previous models. Indeed, by taking a whole input at once, most of their computation can be done in parallel. This results in a dramatic increase in training speed. This makes it feasible to train models on vast datasets within a reasonable timeframe. This ability to train on larger datasets, in turn, significantly improves the model’s performance, as it can learn from a more extensive and varied set of language patterns and structures.
Pretraining and Adaptability to Multiple Tasks
A cornerstone of the Transformer’s revolutionary impact is its ability to be used pre-trained. Models like GPT are initially trained on a massive corpora of text data. Thus, they are capable of learning a wide range of language patterns, structures, and knowledge. This pretraining phase allows the model to develop a deep understanding of language. This can then be prompted to perform a wide variety of specific tasks.
The pretraining process enables the creation of extremely large and computationally expensive models, as this cost is incurred only once. After pretraining, these models can be reused and adapted for many tasks with minimal cost. This makes advanced NLP capabilities accessible for a wide range of applications, even for those without the resources to train large models from scratch.
For reference, GPT-4 is estimated to have required 62 GWh of energy to train or the equivalent energy usage of 15 000 european houses in a year. Open ai incurred a cost of approximately $2 Billion to train the model on over 10 Trillions of words or about 10 Millions books. It required over 25 000 GPU and dozens of days to train. And yet you can use GPT at home and it will answer quickly in a few seconds and require little energy to generate your answer (about 300Wh).
Conclusion
The Transformers architecture has revolutionized the field of Artificial Intelligence. This innovation has enabled machines to interpret, understand, and generate human language with unprecedented accuracy and speed. By overcoming long-term dependency challenges and enabling parallel processing, Transformers have significantly improved the efficiency and effectiveness of language models like GPT. The pretraining process, which involves learning from a vast corpora of text data, has allowed these models to perform a wide array of NLP tasks with little computing power. As a result, NLP models are now accessible to a broader audience.

As an independent AI researcher/developer specialized in Natural Language Processing (NLP), I have a comprehensive expertise in the development and integration of AI systems, as well as data analysis.
Is your company looking to integrate AI solutions, analyze data, or strengthen its back-end development? Contact me!
Mail : pro.judicael.poumay@gmail.com
Linkedin : Judicaël Poumay
Portfolio : www.judicael-poumay.be
- Defining AGI : Why OpenAI’s o3 Isn’t Enough to achieve Artificial General Intelligence - 26 December 2024
- ChatGPT and Large Language Models : Key Historical Milestones in AI - 22 August 2024
- Why non linearity matter in Artificial Neural Networks - 18 June 2024