If you’re familiar with artificial neural networks, you’ve likely heard about activation functions and the significance of their non-linearity. However, I rarely find proper explanations of what non-linearity actually means and why it is so vital for modern neural networks. This article aims to clarify this concept in simple terms and explain its impact on neural networks.
Non-Linearity: Geometry vs. Topology
To understand non-linearity, we need to understand the difference between geometry and topology. Geometry focuses on local properties of spaces, such as distances and angles; it’s all about the details. In contrast, topology concerns global properties. For example, whether a cube is inside a sphere, whether four points lie on the same plane, or if two sets of points are linearly separable.
A linear transformation, such as f(x)=ax+b, affects the geometry of a space by changing distances and angles but does not alter the topology. For example, if we shift the entire space to the right, a cube inside a sphere will remain inside because both move equally. In essence, a linear transformation uniformly modifies the space.
Conversely, a non-linear operation might leave the sphere in place while moving the cube outside of it, applying different changes to different parts of the space. This fundamentally alters the topological properties of the space, changing the answer to questions like “Is the cube inside the sphere?”.
Non-Linear Activation Functions
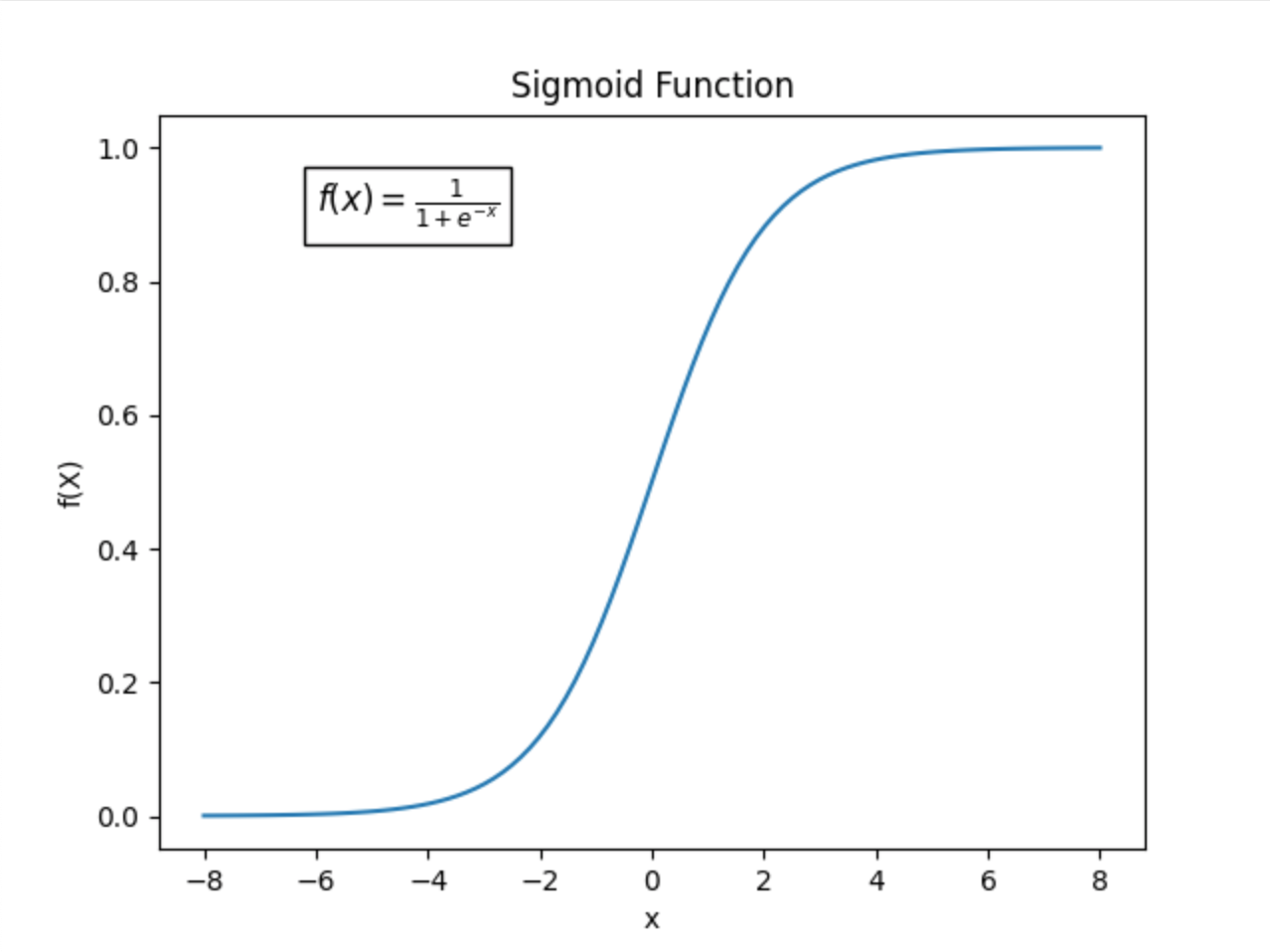
An example of a non-linear operation is the ReLU function. ReLU outputs the input if it is positive, otherwise it outputs 0. Thus, it treats positive and negative parts of the space differently. This function is commonly used in neural networks due to its advantageous properties.
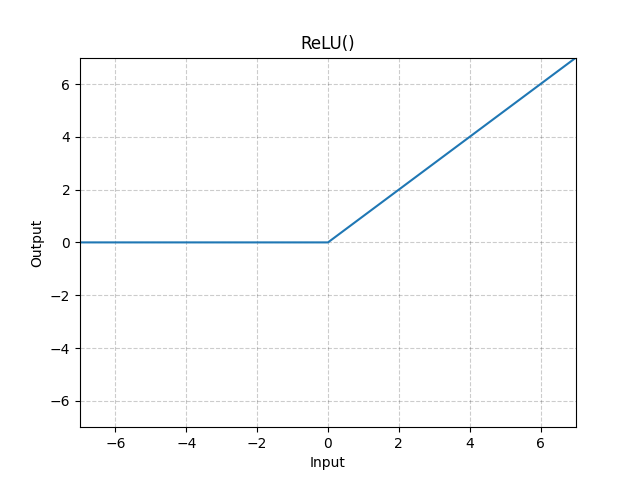
Another example is the sigmoid function, which behaves nearly linearly for values close to 0 but bounds extreme values between 0 and 1. Thus, when applied to an entire space, the sigmoid function affects different regions differently, making it non-linear.
Non-Linearity in Action
Now, let’s see why non-linearity is crucial in neural networks. Through non-linear operations, we can cut, fold, and twist the space as needed. Just as we can move the cube out of the sphere in the previous example, non-linearity in neural networks allows us to manipulate the space to separate sets of points.
A simple example Using ReLU
Consider a simple neural network tasked with separating two sets of points (blue and orange) in a 2D space where one set is inside the other. We cannot separate linearly these points, so we will use a 2-layer ReLU network. Let’s go through each layer step by step.
- Input Layer: The input consists of two variables X1 and X2 which ranges from -6 to 6.
- First Layer: Each neuron of this layer applies ReLU to define positive regions containing only orange points. Each neuron defines a different positive region, and together, they form the borders of the centre of the space.
- Second Layer: This layer sums these regions, creating a region with a value of 0 in the centre and positive values around it. Because ReLU transforms negative values to 0, the sum of these regions remains 0. Thus defining a region in the centre. Finally, by adding a negative bias, this layer defines two regions: one positive and one negative, effectively separating the points.
- Output Layer: The final layer inverses the values to classify the blue points positively.
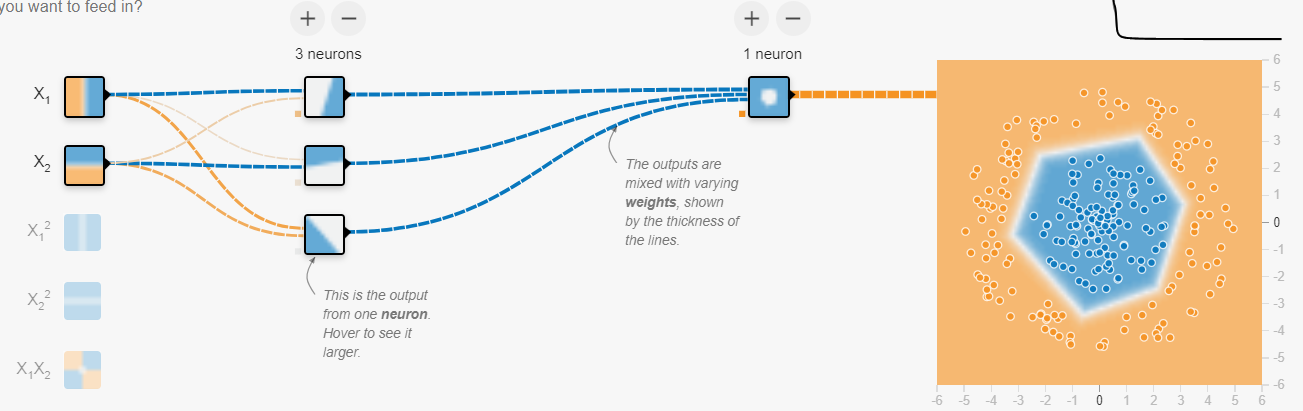
Figure created with the neural playground
As we can see, ReLU is non-linear and affects the space differently in different regions. This characteristic allows us to draw boundaries and define regions in the data space. This non-linear behaviour is found in all activation functions such as sigmoid or tanh.
From this, we can also understand why we need larger models for complex tasks. The space represented by the data related to these complex tasks contains more complex regions. We can also understand the impact of the number of layers and the number of neurons per layer. Wider layers allow us to define more borders and regions, while multiple layers enable us to combine multiple regions into more complex ones. Adding layers to a model leads to exponentially more complex regions. This might explain why we prefer deeper networks to wider ones from a topological perspective.
Conclusion
Non-linearity, despite being a simple concept, is fundamental to neural networks. Understanding neural networks as a series of topological transformations has greatly enhanced my comprehension of their behaviour. While the examples provided are basic, the same principles apply to more complex datasets and models. For instance, a model like GPT with hundreds of layers essentially performs numerous cuts, folds, and twists to differentiate subjects from verbs, proper nouns from common nouns, and more, ultimately predicting the next word in a sequence.

As an independent AI researcher/developer specialized in Natural Language Processing (NLP), I have a comprehensive expertise in the development and integration of AI systems, as well as data analysis.
Is your company looking to integrate AI solutions, analyze data, or strengthen its back-end development? Contact me!
Mail : pro.judicael.poumay@gmail.com
Linkedin : Judicaël Poumay
Portfolio : www.judicael-poumay.be
- Defining AGI : Why OpenAI’s o3 Isn’t Enough to achieve Artificial General Intelligence - 26 December 2024
- ChatGPT and Large Language Models : Key Historical Milestones in AI - 22 August 2024
- Why non linearity matter in Artificial Neural Networks - 18 June 2024