Introduction
L’intelligence artificielle (IA) a connu des avancées importantes au cours de la dernière décennie. Plus spécifiquement, le domaine a été marqué par une démocratisation des grands modèles de langage (LLM) avec la sortie de ChatGPT. Bien que les LLM ne représentent pas l’ensemble du domaine de l’IA, ils en constituent la partie la plus impressionnante à ce jour. Parcourons ensemble cette histoire pour comprendre comment nous en sommes arrivés là.
1950-2012: Préhistoire et hivers difficiles
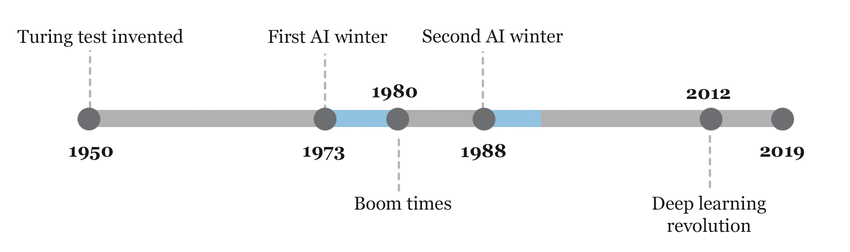
Si nous devions commencer par le début de l’histoire de l’IA, il faudrait remonter aux années 1950. J’ai déjà un article qui traite de l’histoire compliquée des débuts de l’IA, donc nous ne passerons pas beaucoup de temps ici. En bref, ce fut une période difficile pour les chercheurs en IA : bien qu’ils aient eu de bonnes idées, ils ne disposaient pas de la puissance de calcul, des données ou des outils nécessaires pour apprécié la puissance de leurs théories. Cela a conduit à deux périodes nommées « les hivers de l’IA », de 1973 à 1980 et de 1988 à 1993, des périodes où l’optimisme concernant l’IA était affaibli et les financements encore plus.
Néanmoins, beaucoup de travaux importants ont été réalisés entre 1950 et 2012, y compris l’invention du premier réseau de neurones (1958), la procédure d’entrainement des réseaux de neurones : la backpropagation (1974) et de nombreuses architectures neuronales importantes (MLP 1986, RNN 1986, LSTM 1997).
Cependant, c’est cette dernière décennie (2012-2024) qui a vu les plus grandes découvertes dans le domaine de l’IA avec la démocratisation des grands modèles de langage (LLM) tels que GPT. Examinons donc l’évolution de l’IA depuis sa résurgence en 2012. Plus précisément, quelles découvertes ont été essentielles dans l’explosion actuelle de l’IA.
2012: AlexNet, L’essor des réseaux de neurones
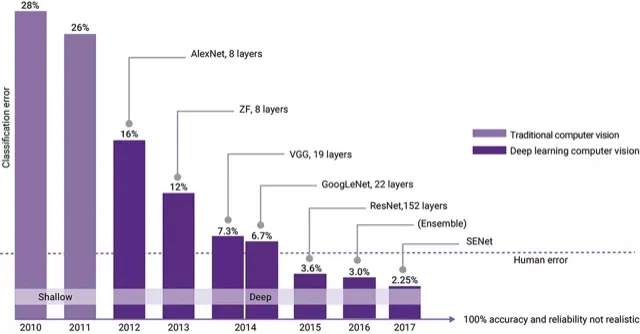
En 2012, AlexNet a révolutionné le domaine de l’apprentissage profond. Bien que les réseaux de neurones datent des années 1950, ils avaient jusqu’en 2012 rencontré peu de succès. Les performances d’AlexNet ont ravivé l’intérêt pour les réseaux de neurones.
AlexNet n’est pas un modèle particulièrement nouveau, mais il a pu profiter de l’évolution de la puissance de calcul et de l’accès aux données de son époque. Cela a permis de démontrer au monde que ce type de modèle pouvait surpasser les méthodes traditionnelles dans des tâches complexes. Son succès a encouragé davantage de recherches en deep learning, ouvrant la voie à des modèles plus sophistiqués dans divers domaines, y compris le traitement automatique du langage naturel (NLP). Pour cette raison, AlexNet est l’un des modèles les plus importants de la communauté de l’IA ; c’est le modèle qui a inauguré l’ère moderne de l’IA, marquant aussi le début de l’ère de la donnée et du deep learning.
2013: word2vec, quand les ordinateurs ont commencé à comprendre les mots
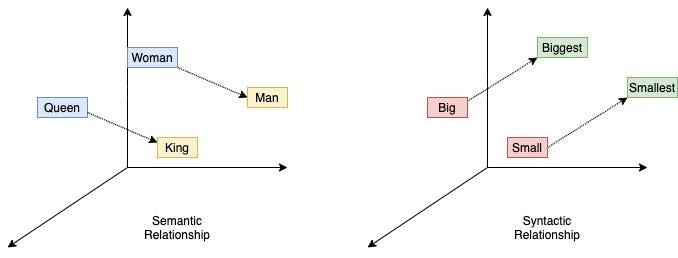
Depuis AlexNet, les chercheurs ont compris que les réseaux de neurones étaient une technologie viable. Cependant, utiliser ces modèles pour l’analyse de texte restait compliqué. Cela a vite changé avec l’introduction de word2vec en 2013, qui a marqué une étape importante dans le traitement du langage naturel (NLP); domaine ou l’IA est appliqué pour analyzer du texte. La sortie de Word2VEC, c’était le jour où les ordinateurs ont appris à comprendre les mots.
Plus précisément, word2vec est une technique basée sur les réseaux de neurones qui transforme les mots en représentations numériques tout en capturant les relations sémantiques entre eux. Ainsi, en utilisant la représentation Word2Vec, la formule suivante est vraie : ROI-HOMME+FEMME=REINE. En reliant les mathématiques et la linguistique, cela a permis aux chercheurs de faire de l’algèbre sur les mots et donc d’analyzer des textes avec des modèles intelligents. C’est le début du NLP basé sur des réseaux de neurones.
2016: fastText, casser les mots en morceaux

En 2016, l’équipe de recherche en IA de Facebook a introduit fastText, une amélioration des solutions de représentation numérique des mots telles que word2vec. FastText a étendu le modèle word2vec en intégrant des informations sur les parties des mots, ce qui lui permet de gérer plus efficacement les mots rares et hors vocabulaire. Plus précisément, fastText crée des représentations pour les parties d’un mot. Par exemple, « inconnu » pourrait être divisé en « in » et « connu», et les deux éléments du mot peuvent être étudiés séparément, fournissant une représentation plus puissante de l’ensemble du mot. Cette approche a permis à fastText de produire des embeddings plus précis et plus robustes, en particulier pour les langues morphologiquement riches.
Ces deux dernières innovations sont communément appelées embeddings statiques de mots, elles représentent des méthodes de représentation des mots en espaces numériques pour un calcul facile par les systèmes d’IA. De nombreux autres embeddings statiques ont été proposés à cette époque. Cependant, ce type d’embedding ont une limitation : la polysémie ou « multiples significations ». Par exemple, des mots comme « souris » peuvent représenter un animal ou un périphérique d’ordinateur selon le contexte. Ces embeddings statiques ne produisaient qu’une seule représentation pour chaque mot, ils ignorent ainsi le contexte dans lequel ils sont utilisés et donc pas mal d’information utile.
2017: Savoir lire, ca demande de l’attention
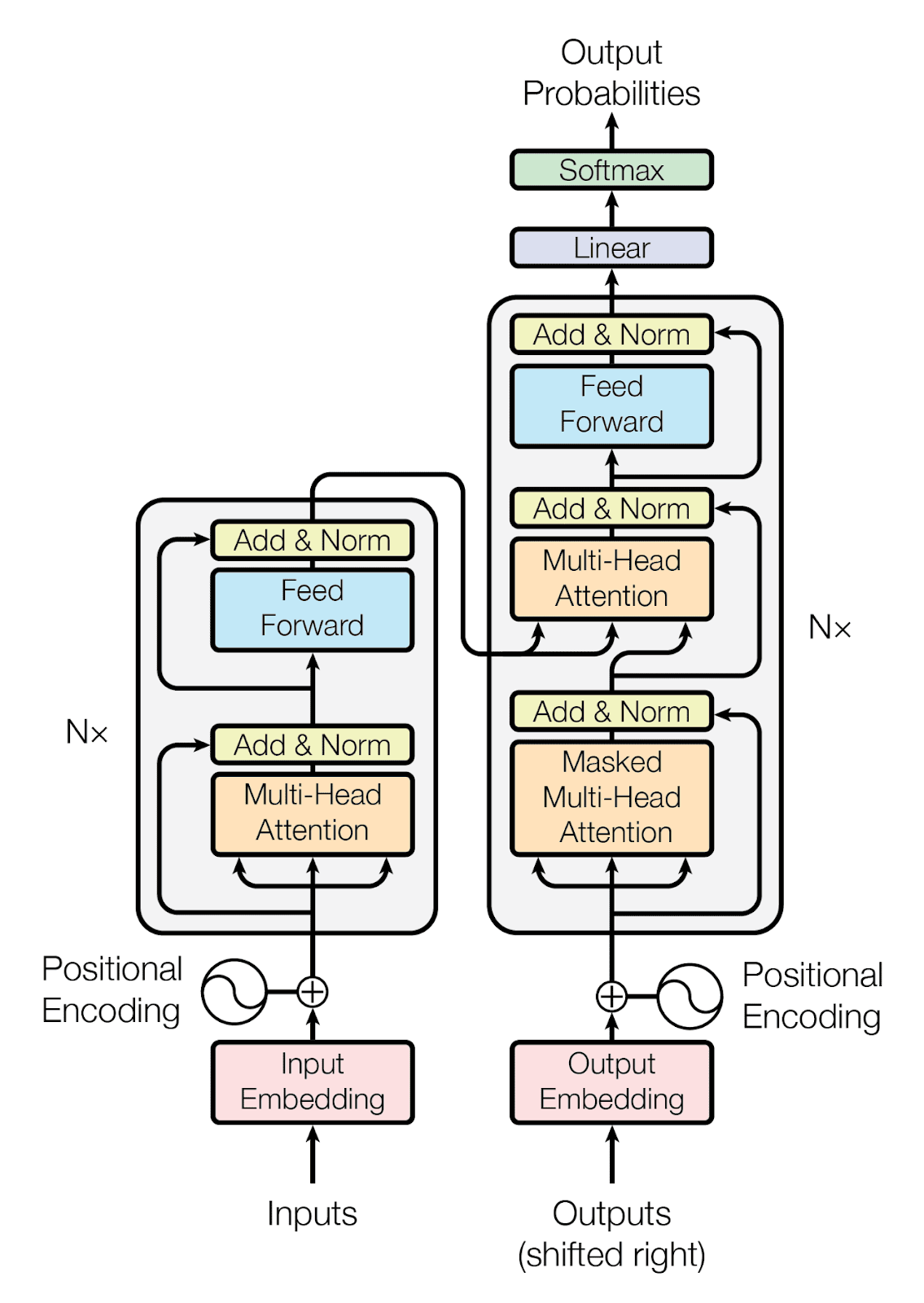
L’article révolutionnaire « Attention is All You Need » a introduit une nouvelle façon de traiter le langage avec les ordinateurs : l’architecture Transformer. Avant cela, les modèles utilisés pour comprendre et générer du texte avaient des limitations, surtout lorsqu’il s’agissait de comprendre des phrases longues et complexes. Le Transformer, grâce à son mécanisme d’auto-attention, a surmonté ces défis en permettant au modèle d’apprendre a lire.
Cette avancée a non seulement accéléré la vitesse d’entraînement des modèles, mais a également permis de créer des modèles beaucoup plus grands et plus puissants. Cela a ouvert la voie à des progrès significatifs dans la compréhension et la génération de texte par les machines.
Le concept d’attention a également permis de mieux gérer la polysémie. Les modèles peuvent ainsi adapter la représentation des mots en fonction de leur utilisation dans la phrase.
La puissance et la flexibilité du concept de l’attention marquent une autre étape clé dans l’évolution du domaine de l’IA. Ce concept marque aussi le début des grands modèles de langage et de la révolution moderne de l’IA et du traitement automatique du langage naturel (NLP).
2018: GPT, ecrire un mot après l’autre
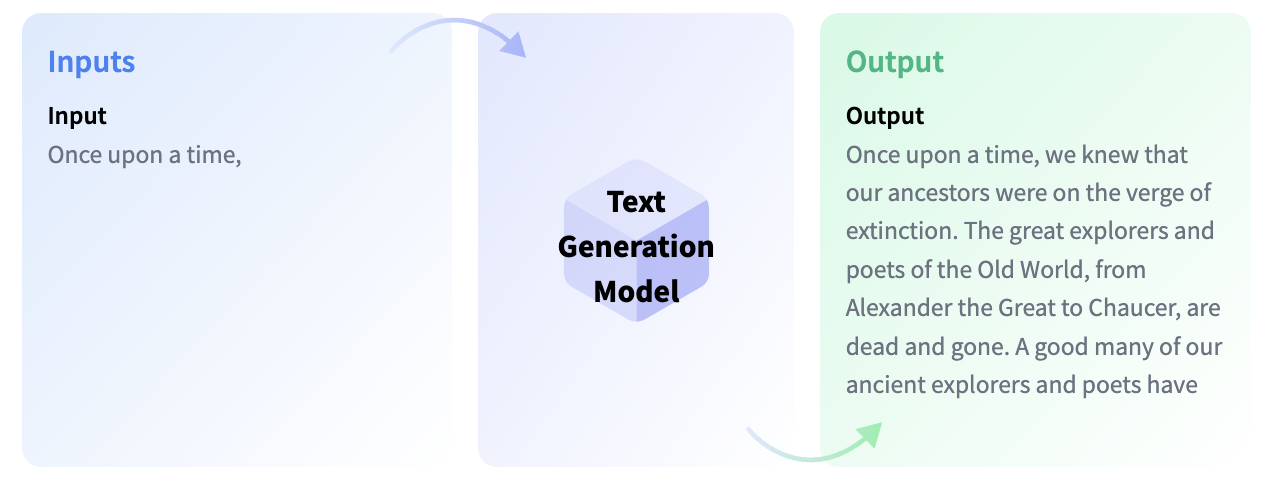
En 2018, OpenAI a introduit GPT. Contrairement à d’autres modèles, qui étaient entraînés à compléter les mots manquants dans les phrases afin de générer des embeddings, GPT a été entraîné à générer le prochain token dans une séquence, ce qui lui a donné la capacité de générer du texte. Cette innovation a conduit à des versions plus puissantes et sophistiquées dans la série GPT. Bien qu’il produise toujours des embeddings contextualisés, sa tâche principale est désormais de générer du texte. Néanmoins, cette première version produisait un texte qui, bien que grammaticalement correct, était incohérent. Maintenant l’IA comment a apprendre a écrire.
2020 & 2022 : GPT-3 & ChatGPT, la democratization de l’IA

GPT-3, publié par OpenAI en 2020, à représenté un bond monumental dans les capacités de l’IA. Avec 175 milliards de paramètres, GPT-3 était le modèle de langage le plus grand et le plus puissant de son époque. Sa taille et son échelle immenses lui ont permis d’accomplir une grande variété de tâches avec un minimum de réglages, allant de la réponse aux questions à la génération de code. La polyvalence et la performance de GPT-3 ont démontré le potentiel des LLMs pour transformer les industries et redéfinir les interactions homme-machine. C’est ce modèle qui est devenu le visage public de l’IA en 2022 avec la sortie de ChatGPT. Cela a changé à jamais le domaine de l’IA, le faisant passer d’un domaine principalement académique à un nom connu de tous.
2024: Modèles Actuels
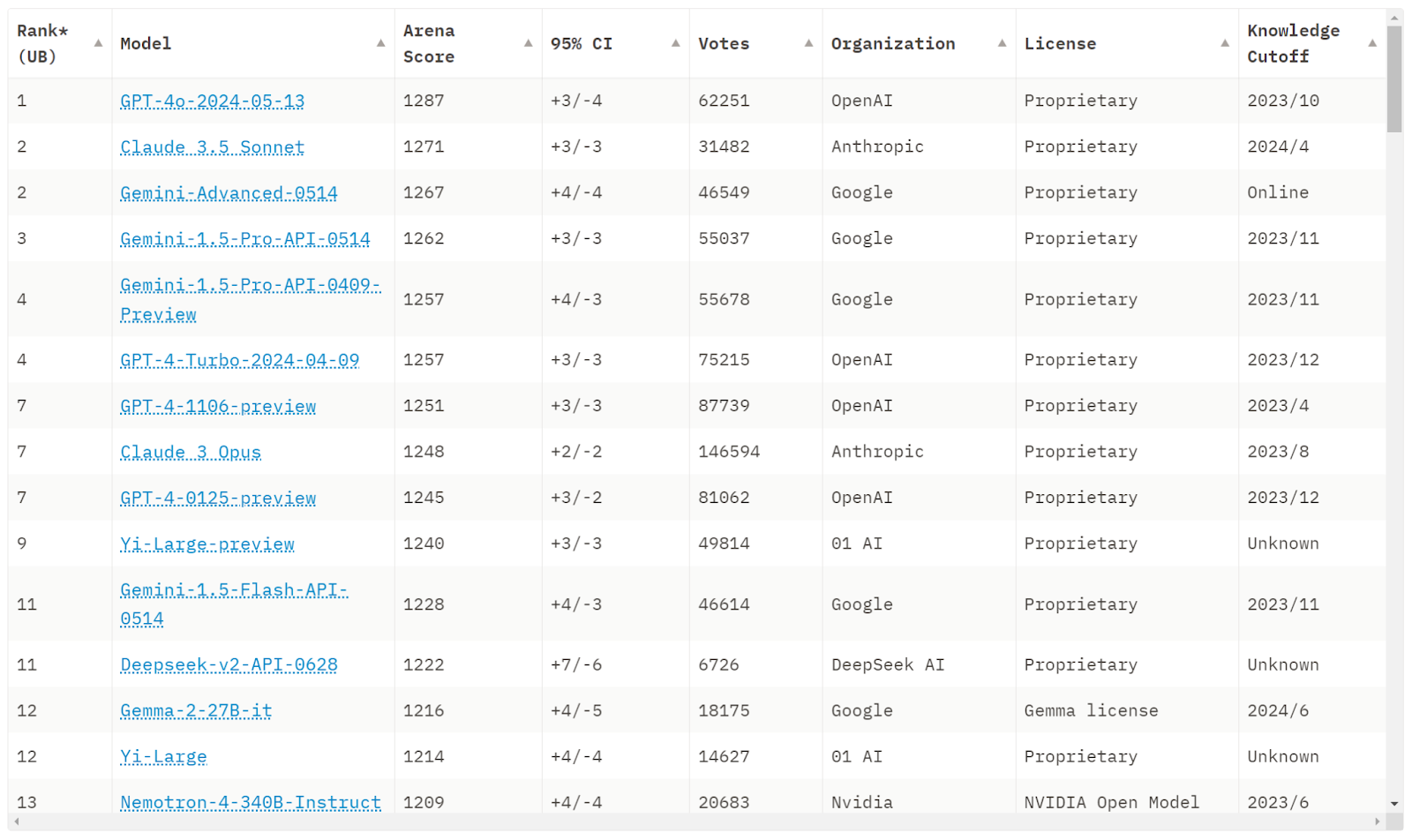
En 2024, le paysage de l’IA et des modèles de langage a continué d’évoluer rapidement. Les modèles actuels tels que GPT-4, LLama, Claude, Gemini, Mistral, Palm, Falcon et Grok représentent la pointe de la technologie en IA et NLP. Bien que chaque modèle diffère légèrement, ils partagent tous la même technologie sous-jacente que nous avons présentée jusqu’à présent. Néanmoins, le dernier modèle d’OpenAI (GPT4o) reste le modèle le plus performant dans l’ensemble, comme nous pouvons le voir sur ce classement : https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard.
Conclusion
L’essor de l’IA, d’AlexNet aux derniers géants des modèles de langage (LLM), reflète les progrès considérables de l’IA et du traitement du langage naturel (NLP) au cours de la dernière décennie. Chaque innovation s’est appuyée sur les précédentes, contribuant aux modèles sophistiqués que nous voyons aujourd’hui. À mesure que l’IA continue de progresser, ces modèles de langage joueront sans aucun doute un rôle central dans la transformation de la technologie, modifiant notre manière d’interagir avec les machines.

En tant que chercheur/développeur indépendant en IA, spécialisé dans le traitement du langage naturel (NLP), j'ai une expertise approfondie dans le développement et l'intégration de systèmes d'IA, ainsi que dans l'analyse de données.
Votre entreprise cherche-t-elle à intégrer des solutions d'IA, à analyser des données ou à renforcer son développement back-end ? Contactez-moi !
Mail : pro.judicael.poumay@gmail.com
Linkedin : Judicaël Poumay
Portfolio : www.judicael-poumay.be