Les réseaux neuronaux artificiels sont l’une des découvertes les plus impressionnantes de l’humanité. Ce sont des structures mathématiques capables d’apprendre un large éventail de tâches, de la traduction automatique à la classification d’images en passant par de meilleurs algorithmes de compression vidéo. Ils sont devenus omniprésents dans le domaine de l’intelligence artificielle, supplantant la plupart des autres techniques.
Cependant, les réseaux neuronaux sont également les outils les plus complexes que nous ayons jamais créés. Avec des modèles tels que Switch-c et son trilliard de paramètres, comprendre ce qui se cache sous le capot de ces machines devient quasiment impossible. En effet, même si nous avons créé et formé ces machines, il est difficile de comprendre ce qu’elles ont appris et comment elles l’ont appris.
L’étude des réseaux neuronaux a donc donné lieu à de nombreux mystères. Nous en aborderons deux : la double descente et le grokking.
La double descente
En classe, on nous apprend que lors du développement d’un modèle tel qu’un réseau de neurones pour une tâche, la complexité de ce modèle doit être limitée pour éviter l’overfitting. En d’autres termes, si un réseau de neurones est suffisamment grand, on s’attend à ce qu’il apprenne simplement par cœur ce qu’on lui enseigne. C’est un problème car cela signifie que le modèle ne peut pas généraliser à de nouvelles situations ; il n’a rien appris. En revanche, un réseau plus petit devrait apprendre à faire entrer les connaissances fournies dans un espace plus restreint, ce qui l’obligerait à apprendre des schémas. Par exemple, dans une tâche linguistique, le modèle pourrait apprendre (ou plutôt découvrir) la syntaxe pour l’aider à comprimer les informations données.
Cependant, le phénomène de double descente est une situation où l’idée mentionnée précédemment est remise en question. C’est-à-dire qu’il existe effectivement une bonne taille de modèle pour laquelle une augmentation ou une diminution réduirait les performances. Cependant, si nous ignorons ce fait et continuons à augmenter la taille du modèle, à un moment donné, les performances s’améliorent à nouveau.
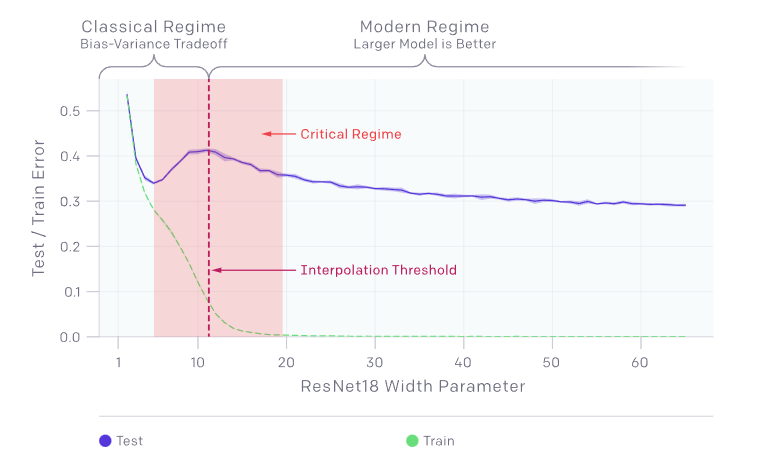
Il est difficile de comprendre ce qui se passe ici. Pourquoi un modèle suffisamment grand pour apprendre par cœur ne saisit-il pas l’occasion si nous le rendons encore plus grand ? Si il ne commet plus d’erreur (car il connaît par cœur), comment le modèle continue-t-il d’évoluer ? Et comment se fait-il que nos théories précédentes restent vraies jusqu’à une certaine taille de modèle ?
Il est intéressant de noter que la taille du modèle à laquelle nos théories précédentes s’effondrent et à laquelle le phénomène se produit correspond exactement à la taille nécessaire pour apprendre par cœur l’ensemble des données fournies. Ceci ne peut pas être une coïncidence, mais la raison nous échappe.
Grokking
Comme toutes les bonnes découvertes, celle-ci est un accident. Un scientifique a oublié d’arrêter l’entraînement de son modèle lorsqu’il est parti en vacances. Lorsqu’il est revenu et a réalisé que le modèle était toujours en train d’apprendre, il a vérifié les résultats. Ce qu’il a trouvé était surprenant.
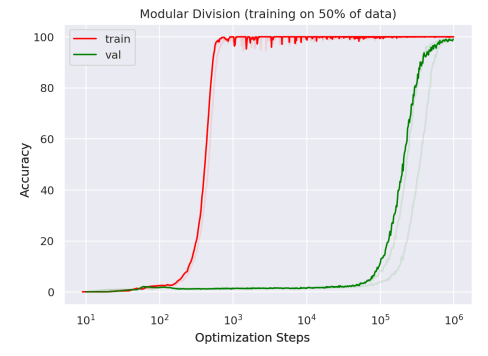
Grokking signifie comprendre de manière approfondie et intuitive. Dans le contexte des réseaux de neurones, il s’agit d’un phénomène lié à la double descente. Cependant, celui-ci est encore plus étrange. Il décrit une situation similaire dans laquelle, si l’on continue à entraîner un modèle sans arrêter, il finira par apprendre à généraliser après overfitting. Plus important encore, l’article montre que ce que le réseau finit par apprendre est parfaitement logique. En d’autres termes, il ne s’agit pas d’un coup de chance, le modèle a réellement appris.
La différence avec la double descente est double. Tout d’abord, en termes d’échelle, car si leur modèle overfit après 1 000 itérations, il recommence à apprendre correctement après 100 000 itérations et ce n’est qu’après un million d’itérations qu’il apprend presque parfaitement.
Deuxièmement, nous n’avons pas de double descente dans ce cas. Ce qui se passe, c’est que nous avons un modèle apparemment incapable de généraliser et qui, au départ, overfit complètement en apprenant les données par cœur. Puis, à un moment donné, sans avertissement, le modèle commence à apprendre. Là encore, on peut se demander comment le modèle a réussi à réellement apprendre alors qu’il avait d’abord tout retenu par cœur, mais aussi pourquoi il n’a pas appris plus tôt ?
Note de fin
La double descente et le grokking jettent des doutes sur notre compréhension des réseaux de neurones et de leurs procédures d’entraînement. Ces phénomènes vont à l’encontre de nos théories fondamentales qui veulent que des modèles plus simples sont préférables pour éviter l’overfitting et que l’arrêt précoce de l’entrainement est bénéfique. Cependant, nous savons, ou du moins nous avons observé depuis longtemps, que des modèles plus grands ont tendance non seulement à être plus performants, mais aussi à être entraînés plus rapidement que des modèles plus petits.
Bien que ces phénomènes restent mystérieux, leurs compréhension pourrait potentiellement conduire à une révolution dans la façon dont nous formons les réseaux de neurones, car il serait plutôt pratique de pouvoir déclencher le Grokking à la demande ou d’accélérer la double descente.

En tant que chercheur/développeur indépendant en IA, spécialisé dans le traitement du langage naturel (NLP), j'ai une expertise approfondie dans le développement et l'intégration de systèmes d'IA, ainsi que dans l'analyse de données.
Votre entreprise cherche-t-elle à intégrer des solutions d'IA, à analyser des données ou à renforcer son développement back-end ? Contactez-moi !
Mail : pro.judicael.poumay@gmail.com
Linkedin : Judicaël Poumay
Portfolio : www.judicael-poumay.be