Voici un problème: les ordinateurs communiquent avec des nombres et nous communiquons avec des mots. Comment donc apprendre aux ordinateurs à comprendre notre langue? Et si nous pouvions transformer les mots en nombres sans perdre leur sens? La réponse est l’embedding de mots! Une technique de la NLP que je vais vous présenter dans cet article.
L’embedding de mots
Embedder un mot, c’est le transformer en un vecteur de nombres. Un exemple fictif pourrait être “chat” = [0.5,0.9] mais en réalité de tels vecteurs sont souvent composés de centaines de nombres (ou dimensions).
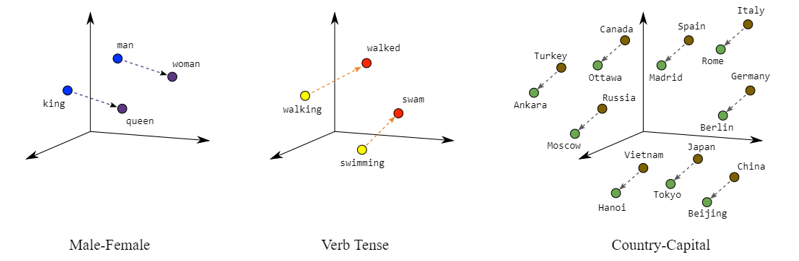
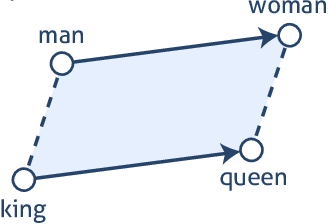
Embedder des mots les projette dans un espace mathématique; nous supposerons ici un espace 2D. Pour la plupart des embedders, cela conduit à deux conséquences intéressantes. Premièrement, les mots qui sont contextuellement similaires seront plus proches les uns des autres tels que cuisine, évier et table tandis que des mots comme four et béton seront plus éloignés. Deuxièmement, il devient possible d’effectuer des opérations arithmétiques sur des mots tels que : roi – homme + femme = reine.
L’embedding statique de mots
Les mots similaires apparaissent dans des contextes (mots environnants) similaires . Par conséquent, les ordinateurs peuvent apprendre quels mots sont similaires en comparant leur contexte. De là, les ordinateurs comprennent que «chat» et «chien» sont similaires tout en étant différents de «couteau». C’est l’idée derrière Word2Vec.
Ces types d’embedding peuvent être appelés «embedding statique». Les trois exemples principaux d’embedders sont Word2Vec, GloVe et FastText.
GloVe est basé sur Word2Vec et ajoute des informations statistiques. Par conséquent, les mots qui apparaissent ensemble sont plus susceptibles d’avoir des vecteurs similaires. Plus précisément si « chat » et « chien » apparaissent 20 fois ensemble : chat x chien ~= log (20).
FastText, est également basé sur Word2Vec et considère les partie de mots. Par exemple, FastText transforme «artificiel» en <ar, art, rti, tif, ifi, fic, ici, iel, el>, puis calcule l’embedding pour chaque partie du mot. L’embedding final du mot est une combinaison des embedding de ses parties. Cela a de multiples conséquences. Tout d’abord, FastText comprend mieux les préfixes et suffixes en se concentrant sur les sous-partie de mots. Deuxièmement, comme il y a moins de sous-parties possibles que de mots, FastText a besoin de moins de données pour être entraîné. Enfin, FastText est capable de gérer des mots qu’il n’a jamais vus tant qu’il a vu ses sous-parties alors que word2vec et GloVe ne le peuvent pas.
L’embedding dynamique de mots
Le langage humain est complexe. Prenez la phrase : ”Il est né à l’est”. Nous avons deux fois le mot “est” mais il signifie deux choses différentes. Par conséquent, si le mot “est” a le même embedding à tout moment, l’ordinateurs ne pourra pas différencier entre ces choses.
La solution c’est «l’embedding dynamiques» ou «contextuelles». L’embedding dynamique modifie l’embedding d’un mot en fonction de son contexte. De nombreux embedder existent à cet effet, mais les plus connus sont BERT et ELMO. Les deux prennent l’embedding statique d’un mot et l’enrichissent d’informations contextuelles. Une façon simple est de mélanger l’embedding d’un mot avec l’embedding des mots qui l’entourent.
Autre embedding
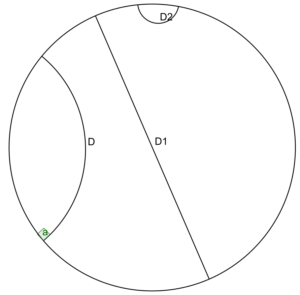
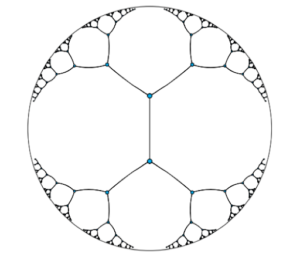
D’autres embedding de mots existent et l’embedding de Pointcarré est particulièrement intéressant. Il s’agit d’un embedding hiérarchique hyperbolique. Hyperbolique est le type de géométrie de l’espace mathématique. Dans la figure (a), D, D1 et D2 sont toutes des lignes droites dans cet espace. Cela peut être troublant pour ceux qui ne sont pas habitués à la géométrie non euclidienne, mais cela a des propriétés incroyables. En utilisant cet espace, nous pouvons embedder des mots dans des vecteurs non pas en regardant leur signification mais plutôt leur structure hiérarchique comme dans la figure (b). Traduit en géométrie hyperbolique et nous avons la figure (c) dans laquelle chaque ligne que vous voyez a la même longueur. Dans ce type d’embedding, les mots sont plus proches d’autres mots taxonomiquement similaires et plus éloignés des autres.

(a) Exemples de lignes droites dans l’espace hyperbolique 
(c) Espace hyperbolique rempli d’embedding de Pointcarré

(b) Exemple de taxonomie
Conclusion
En NLP, l’embedding des mots est l’un des outils les plus utilisés. La capacité de transformer un mot en un vecteur de nombre tout en conservant un sens en fait une solution flexible. Les tâches qui utilisent l’embedding incluent le balisage POS, NER, l’extraction d’opinion, les systèmes de recommandation et bien d’autres.

En tant que chercheur/développeur indépendant en IA, spécialisé dans le traitement du langage naturel (NLP), j'ai une expertise approfondie dans le développement et l'intégration de systèmes d'IA, ainsi que dans l'analyse de données.
Votre entreprise cherche-t-elle à intégrer des solutions d'IA, à analyser des données ou à renforcer son développement back-end ? Contactez-moi !
Mail : pro.judicael.poumay@gmail.com
Linkedin : Judicaël Poumay
Portfolio : www.judicael-poumay.be