Here is a problem: computers communicate with numbers and we communicate with words. How can we therefore teach computers to understand our language? What if we could transform words into numbers without losing their meaning in the process? The answer is word embedding! A technique of NLP that I will present in this article.
Word Embeddings
To embed a word is to transform it into a vector of numbers. A fictitious example could be “cat” = [0.5,0.9] but in reality such vectors are often made up of hundreds of numbers (or dimensions).
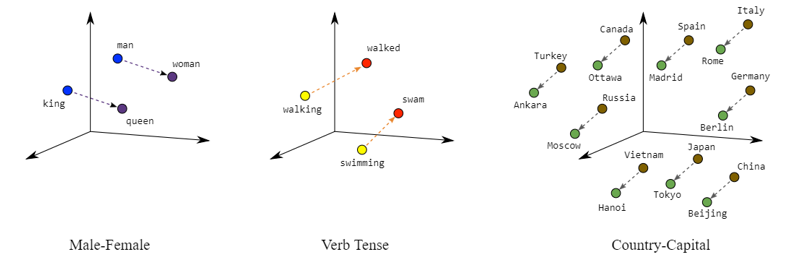
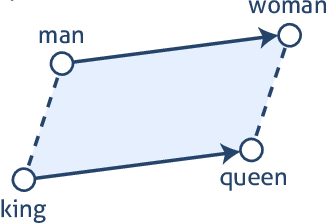
Embedding words projects them into a mathematical space; we will assume a 2D space here. For most embedders this leads to two interesting results First, contextually similar words will be closer together such as kitchen, sink, and table while words like oven and concrete will be farther apart. Second, it becomes possible to perform arithmetic operations on words such as : king – man + woman = queen.
Static word embedding
Similar words appear in similar contexts (surrounding words). Therefore, computers can learn which words are similar by comparing their context. From this the computers understand that “cat” and “dog” are similar while different from “knife”. This is the idea behind Word2Vec.
These kinds of embeddings can be called “static embedding”. The three prime examples of such embedders are Word2Vec, GloVe, and FastText.
GloVe is based on Word2Vec and adds statistical information. Hence, words that appear together are more likely to have similar vectors. More precisely if “cat” and “dog” appear 20 time together : cat x dog ~= log(20).
On the other hand, FastText, which is also based on Word2Vec, considers the part of words. For example, FastText transforms “artificial” into and then computes the embedding for each part of the word. The final word embedding is a combination of these lower-level embeddings. This has multiple consequences. First, FastText understands prefixes and suffixes better by focusing on sub-part of words. Second, since there are less possible sub-part than words, FastText needs less data to be trained. Finally, FastText is able to handle words it has never seen as long as it has seen its sub-parts while word2vec and GloVe can’t.
Dynamic word embedding
Human language is messy. Let me ask you : what is a bass? A type of fish or a musical instrument? You can’t tell but if I tell you “I ate a bass” then you can say that I am talking about a fish. The meaning of bass depends on its context. Therefore, if the word “bass” has the same embedding at all times, computers won’t tell the difference between a fish and an instrument.
The solution is “dynamic” or “contextual” embeddings. Dynamic embedder changes the embedding of a word depending on its context. Many embedders exist for this purpose, but the most well known are BERT and ELMO. Both take static embedding as input and augment them with contextual information. One simple way to do this is to mix the embedding of a word with the embedding of the words surrounding it.
Other embedding
Other word embeddings exist and Pointcarré embedding is particularly interesting. It is an hyperbolic hierarchical embedding. Hyperbolic is the type of geometric of the mathematical space. In the figure (a), D,D1, and D2 are all straight lines in this space. This can be unsettling for those who are not used to non-euclidean geometry but it has amazing properties. Using this space, we can embed words into vectors not by looking at their meaning but rather their hierarchical structure as in figure (b). Translated in hyperbolic geometry and we have figure (c) in which each line you see has the same length. In this kind of embedding words are closer to other words that are taxonomically similar and farther apart from others.
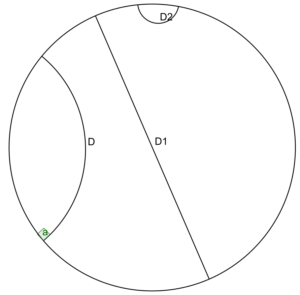
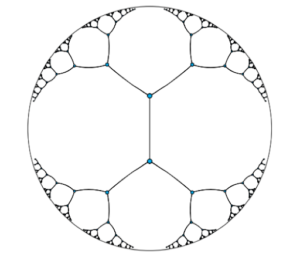
Pointcarré embedding
Conclusion
In NLP word embedding is one of the most used tools. The ability to transform a word into a vector of number while retaining meaning makes it a flexible solution. Tasks that use embedding include POS tagging, NER, Opinion mining, recommender system, and many others.

As an independent AI researcher/developer specialized in Natural Language Processing (NLP), I have a comprehensive expertise in the development and integration of AI systems, as well as data analysis.
Is your company looking to integrate AI solutions, analyze data, or strengthen its back-end development? Contact me!
Mail : pro.judicael.poumay@gmail.com
Linkedin : Judicaël Poumay
Portfolio : www.judicael-poumay.be
- Python Release History (2026): From 3.0 to 3.15 What Changed? - 15 March 2026
- How to Setup Azure SSO with FastAPI: A Complete Guide - 18 October 2025
- Why is the AI revolution so slow? (It’s not) - 18 September 2025