Cet article est le premier d’une série dans laquelle je vais tenter d’expliquer les réseaux de neurones aussi simplement que possible. Les réseaux neuronaux artificiels sont aujourd’hui les outils les plus omniprésents et les plus complexes dans le domaine de l’intelligence artificielle. Dans de nombreux cas, ils sont composé de millions de neurones et apprenne à résoudre des tâches avec des capacité surhumaine. Par example, jouer aux échecs ou aider les médecins dans leurs diagnostics. Dans cet article, j’expliquerai à l’aide d’exemples simples comment les réseaux de neurones prennent des décisions.
Pourquoi est-ce que l’on utilise des réseau de neurones?
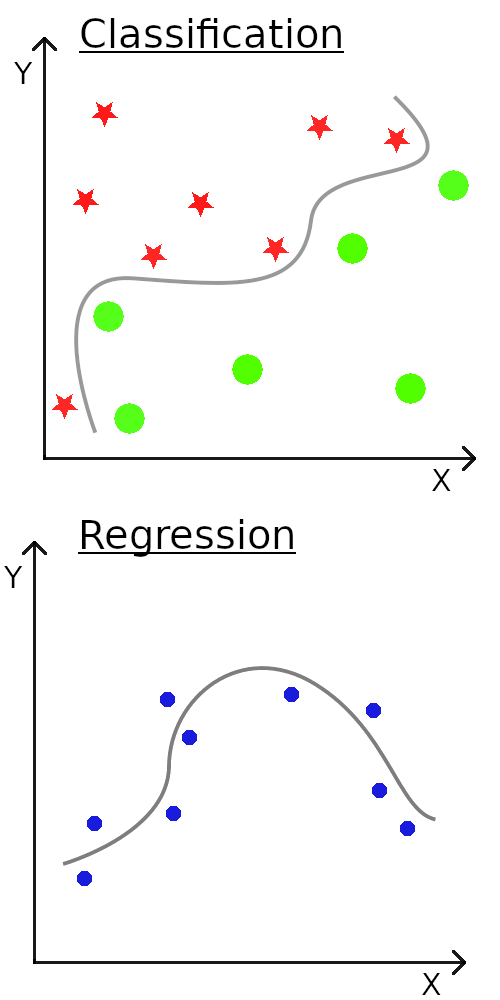
Une bonne façon de comprendre un outil est de comprendre ce qu’il fait. Pour les réseaux de neurones, il y a deux tâches principales : la classification et la régression. Nous allons nous concentrer sur la classification.
La classification consiste à déterminer le type de quelque chose. Par exemple, pour un groupe de mail, décider ce qui est du spam et ce qui ne l’est pas ou à partir d’une image d’un animal, décider si c’est l’image d’un chat, d’un chien ou autre chose. Mathématiquement, cela signifie tracer une frontière entre deux ou plusieurs ensembles de points.
Si chaque point représente un mail, sa position est déterminée par une dimension que nous avons mesurée, comme la qualité de l’écriture (grammaire et orthographe) et si oui ou non l’expéditeur est connu. Décider quoi mesurer et comment le mesurer est une tâche difficile en soi appelée feature engineering. Mon article sur l’embedding des mots est un exemple d’entrée souvent utilisé dans les réseau de neurones.
Un réseau de neurones
Supposons que nous voulions classer des mail comme étant des spams ou non. Ce que nous voulons, c’est un réseau de neurones qui prend en entrée la représentation d’un mail d’une manière ou d’une autre (qualité de l’écriture, authenticité, style, contenu, titre, …). Et ensuite, à partir de ces données, décide s’il s’agit de spam ou non.
Un réseau de neurones dans sa forme la plus simple est un groupe de neurones disposés en couches et reliés entre eux. L’information entrée traverse le réseau de gauche à droite et sort à l’autre bout avec une réponse.

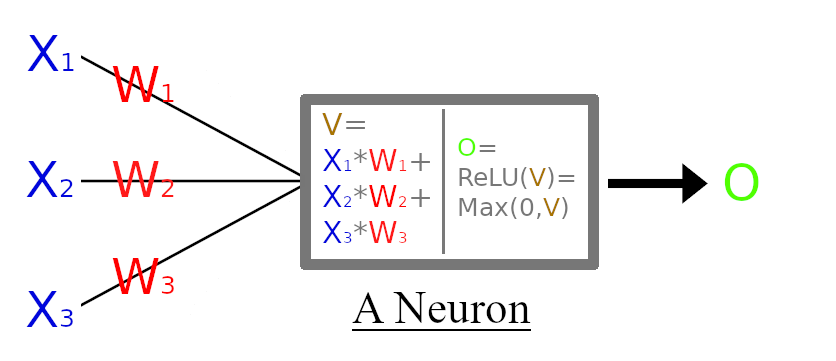
Chaque neurone (sauf pour la couche d’entrée) prend les valeurs produites par les neurones de la couche précédente et les multiplie par ce qu’on appelle des poids qui représente la force des liens entre les neurones. Ensuite, nous faisons la somme de ces valeurs, et le résultat est transmis à une fonction d’activation qui calcul la sortie finale du neurone. Les fonctions d’activation ne sont pas très importante ici, je les expliquerai dans un autre article. Cette valeur finale sera elle-même soit utilisée par la couche suivante ou fera partie de la sortie finale du réseau.
Les neurones sont organisés en couches. La couche d’entrée sert uniquement à stocker les valeurs d’entrée, les couches internes dites cachées transforment l’entrée et la couche de sortie prend la décision finale. Chaque couche, à l’exception de la première, prend en entrée le résultat des neurones de la couche précédente et produit un résultat pour chacun de ses neurones. Par conséquent, l’information circule dans le réseau de gauche à droite et est transformée en réponse.
Le fonctionnement interne
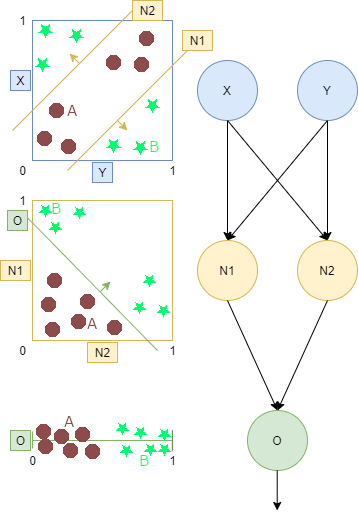
Que se passe-t-il réellement dans un réseau ? Prenons un simple réseau 2x2x1 et un jeu de points à séparer représentant des mails. Nous avons deux entrées (X,Y), deux neurones cachés (N1,N2) et un neurone de sortie (O).
L’entrée (X,Y) forme un espace à 2 dimensions. X et Y peuvent être tout ce que nous voulons tant que c’est mesurable (qualité de l’écriture, authenticité, style, …). En regardant l’image à droite, l’espace d’entrée se trouve au dessus au gauche. Pour la suite, nous dirons que les cercles rouges sont de bon mail tandis que les étoiles vertes sont des spams.
Nous pouvons imaginer que chaque point de l’espace d’entrée (X,Y) passe par la couche cachée et produit un nouvel espace (N1,N2), également appelé espace latent. Ce nouvel espace est produit car chacun des deux neurones cachés trace une ligne dans l’espace d’entrée.
Les cercles rouges dans l’espace d’entrée sont séparés des étoiles vertes par ces deux lignes. Comme vous pouvez le voir, ces deux lignes ont une flèche qui pointe à l’opposé de cercles rouges. Cela signifie que pour N1 ou N2, les étoiles vertes ont une valeur plus élevée que les cercles rouges.
Nous pouvons voir comment les points A et B ont évolué avec cette transformation. Les cercles rouges sont déplacés vers le bas à gauche car ils ont une faible valeur pour les deux neurones, tandis que les étoiles vertes sont déplacées vers la droite ou vers le haut car elles ont une valeur élevée pour un des deux neurone.
Le dernier neurone de sortie transforme cet espace latent en un espace à une dimension puisque la couche de sortie ne possède qu’un seul neurone. De même, cela signifie que nous traçons une ligne dans l’espace latent séparant une fois de plus les cercles rouges (bon mail) et les étoiles vertes (spam).
A la fin, nous avons un score qui indique à quelle point le réseau pense que l’entrée représente un spam. En effet, les étoiles vertes ont un score plus élevé que les cercles rouges. Notez que cet exemple est fictif et qu’en réalité, les données sont beaucoup plus complexes, tout comme le réseau de neurones.
Conclusion
Dans cet article, j’ai expliqué comment les réseaux de neurones prennent des décisions. Mais les réseaux neuronaux doivent être entraîné afin d’apprendre quelles sont les bonnes décisions. Dans le prochain article de cette série, j’expliquerai comment les réseaux sont entraîné.

En tant que chercheur/développeur indépendant en IA, spécialisé dans le traitement du langage naturel (NLP), j'ai une expertise approfondie dans le développement et l'intégration de systèmes d'IA, ainsi que dans l'analyse de données.
Votre entreprise cherche-t-elle à intégrer des solutions d'IA, à analyser des données ou à renforcer son développement back-end ? Contactez-moi !
Mail : pro.judicael.poumay@gmail.com
Linkedin : Judicaël Poumay
Portfolio : www.judicael-poumay.be