Les modèles de langage de grande taille (LLMs) font désormais partie de nos vies, mais comment sont-ils si efficaces? Quel est l’élément essentiel qui rend les LLM si puissants ? La réponse se trouve dans le titre de l’article scientifique le plus important qui a conduit à la création des LLMs : “Attention is all you need” qui nous a donné le mécanisme d’attention moderne.

Le mécanisme d’attention est l’un des concepts les plus importants dans les systèmes d’IA actuels. Inspirée par la capacité humaine à se concentrer sélectivement sur certaines choses, l’attention permet aux réseaux neuronaux de prioriser les informations les plus pertinentes. Ainsi, les IA ont une compréhension beaucoup plus ciblée du problème qui leur est donné. Dans cet article, je vais essayer de clarifier la complexité derrière l’attention sans trop simplifier.
Pourquoi l’attention est-elle si importante ?
Le monde est un endroit complexe, bien plus que nous ne le réalisons. Notre cerveau humain a évolué sur des millions d’années pour ignorer la plupart des choses du monde. Pourquoi ? Parce que 1) la plupart des choses sont sans importance, et 2) il existe presque une infinité d’informations autour de vous. Votre cerveau trie donc l’information. Vous souvenez-vous de la couleur du sol dans votre supermarché habituel ? Probablement pas. Vous n’y pretez pas d’attention.
Moins vous remarquez des choses sans importance, plus vous pouvez consacrer du temps de cerveau à ce qui compte vraiment. Cette incroyable capacité à décider ce qui est pertinent nous rend efficaces, nous permettant de résoudre des problèmes complexes. Nous avons développé cette capacité au cours de millions d’années d’évolution; pour nous, c’est tellement évident que nous ne le réalisons pas, mais pour l’IA, ce n’est pas le cas.
Les systèmes d’IA ne prêtent pas attention par défaut. Sans attention, si vous demandez à une IA basique de classer des images de chats et d’oiseaux, que voit-elle ? Tout ; elle voit chaque pixel, elle remarque la couleur du sol, et cela n’est pas utile. Ainsi, l’IA doit apprendre où regarder et quoi filtrer, mais comment ? Dans le cas des grands modèles de langage (LLM), quels mots sont les plus importants pour comprendre et répondre à une requête ?
Que signifie pour un LLM de prêter attention ?
L’attention dans les modèles de langage (LLM) permet à chaque mot d’une phrase d’être pondéré en fonction de sa pertinence. Plutôt que de traiter chaque mot de manière uniforme, l’attention réattribue dynamiquement l’importance, garantissant que les mots et phrases clés reçoivent plus d’attention.
Voici un exemple pratique. Si je demande à un LLM :
« S’il te plaît, GPT, peux-tu me dire quel est l’animal de compagnie le plus probable dans une maison? »
Il se concentrera sur ce qu’il considère comme l’élément le plus important de la question, dans ce cas « quel », « probable », « animal de compagnie » et « maison ». En réponse, il parlera probablement des chats et des chiens. Le modèle de langage accorde moins d’attention aux mots comme « s’il te plaît, GPT » car ils ne sont pas pertinents pour la question posée.
Le mécanisme d’attention permet aux LLM de contextualiser les mots pour aider le modèle à mieux comprendre un problème donné. Sans cela, l’IA verrait chaque mot d’un texte, sans comprendre comment ils sont liés. Par exemple, les verbes sont liés aux sujets. Ainsi, le mécanisme d’attention peut associer un sujet à un verbe. Ensuite, lorsque le modèle rencontre le verbe, il ne verra pas simplement un mot, mais saura aussi quel sujet y est lié. En d’autres termes, maintenant, lorsque le LLM voit le verbe, il peut aussi prêter attention au sujet qui lui est associé.
Les mathématiques derrière le mécanisme d’attention
Maintenant que nous comprenons l’idée de base, voyons si nous pouvons décomposer les mathématiques derrière le mécanisme d’attention. Tout d’abord, nous aurons besoin d’un peu de contexte.
Une note sur les embeddings
Les mots sont des éléments du langage humain, mais les LLMs sont des systèmes mathématiques qui ne comprennent que les chiffres. Par conséquent, en pratique, nous devons traduire les mots en structures mathématiques pour que les LLM puissent les manipuler. Vous pouvez en apprendre davantage dans cet article si cela vous intéresse.
En résumé, les mots sont représentés par des vecteurs de manière à ce que ces vecteurs encodent le sens des mots. Maintenant que les mots sont traduits dans un espace mathématique, nous pouvons faire des mathématiques avec les mots. Par exemple, ROI-HOMME+FEMME=REINE est une formule vraie dans cet espace vectoriel. Nous appelons cette méthode l’intégration de mots (word embeddings) car nous intégrons les mots dans un espace vectoriel.
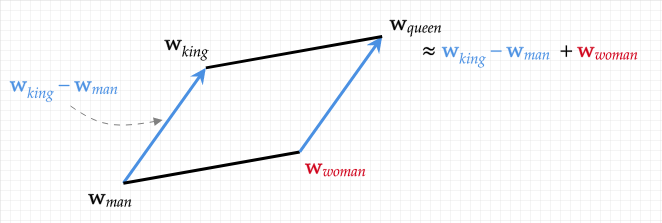
L’idée principale derrière le mécanisme d’attention est d’utiliser une représentation de base et de produire une représentation plus complexe qui inclut le contexte. Par exemple, dans la phrase « La souris mange du fromage », le mot souris seul est ambigu. Ainsi, nous voulons un moyen de contextualiser correctement le mot souris afin que le modèle comprenne qu’il s’agit d’un animal et non d’un périphérique d’ordinateur. C’est ce que fait le mécanisme d’attention.
Pour ce faire, nous prenons une représentation vectorielle générale du mot souris appelée embedding statique; elle encode le mot souris dans toutes ses significations possibles. Ensuite, nous essayons de créer une nouvelle représentation sourisnouvelle = souris + fromage, créant ainsi une nouvelle représentation contextualisée. Cela signifie que lorsque le modèle voit la représentation vectorielle sourisnouvelle, il verra également une partie de la représentation du mot fromage et comprendra mieux ce que signifie le mot souris dans ce contexte. Donc, Il fait attention aux autres mots afin de mieux comprendre.
Une note sur la similarité
Pour décider à quoi prêter attention, le modèle doit mesurer à quel point deux mots sont liés. Cela peut être fait en prenant le produit vectoriel de leurs embeddings. Lorsque vous multipliez deux embeddings/vecteurs élément par élément et que vous additionnez les résultats, vous obtenez un seul scalaire : le produit vectoriel. Si deux embeddings de mots pointent dans des directions similaires, leur produit scalaire est grand, sinon, il est petit ou négatif.
Dans le monde des embeddings, pointer dans la même direction signifie avoir un sens similaire. Par exemple, les embeddings pour « chat » et « chien » existent dans un champ lexical similaire ; ils apparaissent dans des contextes similaires. Ainsi, leur produit scalaire est élevé. En revanche, « chat » et « dette » partagent rarement les mêmes contextes. Cela produit un score beaucoup plus bas.

De plus, les embeddings contiennent beaucoup plus d’informations sur les mots que leur simple signification. Par exemple, ils encode également des informations syntaxiques telles que, en général, les produits scalaires entre nom et nom sont plus élevés que ceux entre nom et verbe. Nous pouvons utiliser ces propriétés pour produire un mécanisme d’attention puissant.
Comment calculer l’attention : un exemple trivial
Version simplifiée de la formule de l’attention
La formule complète de l’attention est un peu complexe : O=softmax(scale(QKT))V. Simplifions certaines choses. Mettons de côté le softmax et le scaling pour l’instant ; ils ne nous aideront pas à comprendre.
Nous devons maintenant comprendre le reste de la formule, O = QKTV. Les matrices Q, K et V sont définies comme suit :
- La requête (query) Q = I*MQ
- La clé (key) K = I*MK
- La valeur (value) V = I*MV
Les MQ, MK, et MV sont également des matrices et leurs valeurs sont apprises; c’est ce que nous faisons lorsque nous entraînons un LLM. Nous en parlerons plus tard; ignorons-les pour l’instant afin de comprendre une formule encore plus simple. Cela signifie que nous avons maintenant O = IITI.
Calcul d’une matrice de similarité simplifiée
Maintenant, la formule est beaucoup plus simple : O = IITI. Que se passe-t-il ici ? Prenons un simple texte simple, par exemple « la souris mange du fromage », nous produisons une séquence d’embeddings d’entrée I = (i1,…,in) représentant une liste de vecteurs (la, souris, mange, du, fromage). Ainsi, la matrice I est définie comme une séquence d’embeddings de mots représentant le texte d’entrée.
Tout d’abord dans notre formule, nous multiplions I et IT. Cela signifie multiplier (la, souris, mange, du, fromage) par sa transpose. Par conséquent, cela produit une nouvelle matrice 5×5 comme indiqué ci-dessous. Comme vous pouvez le voir, nous multiplions chaque vecteur de mot dans la matrice I par chaque autre. Rappelez-vous, cela signifie que nous calculons la similarité entre chaque mot comme expliqué ci-dessus.
| la*la | souris*la | mange*la | du*la | fromage*la |
| la*souris | souris*souris | mange*souris | du*souris | fromage*souris |
| la*mange | souris*mange | mange*mange | du*mange | fromage*mange |
| la*du | souris*du | mange*du | du*du | fromage*du |
| la*fromage | souris*fromage | mange*fromage | du*fromage | fromage*fromage |
Utilisons des valeurs de similarité fictives pour simplifier les choses. Par exemple, souris*souris=1 parce qu’il s’agit du même mot. souris*fromage est proche de 1 parce qu’ils apparaissent souvent ensemble. En continuant pour chaque valeur, nous produisons une nouvelle matrice S égale à IIT, qui mesure a quel point chaque mot est lexicalement lié aux autres. Appelons cela la matrice de Similarité.
Calcul d’un mécanisme d’attention simplifié
Ensuite, nous pouvons calculer le reste de la formule IITI= SI, en multipliant S et I. Multiplier S par I crée une nouvelle matrice O = SI = (sourisO, mangeO, duO, fromageO). Cela à pour effet de produire de nouveaux embeddings pour chaque mot qui sont un mélange pondéré des embeddings d’entrée originaux.
Par exemple, sourisO est égale à mange*(souris*mange) + du*(souris*du) + fromage*(souris*fromage) + souris*(souris*souris). Ainsi, sourisO est un mélange de l’encodage de tous les autres mots dans la séquence d’entrée, pondéré par leur similarité. Par exemple, sourisO=mange*0.4 + du*0.2 + fromage*0.8 + souris*1. Notez que souris*souris=1 puisqu’il s’agit du même mot, et fromage*souris=0.8 puisqu’ils sont lexicalement liés. Cela signifie que cette nouvelle représentation du mot souris contient également une partie de la representation du mot fromage. Nous avons produit un nouvel embedding contextualisé.
Calcul de l’attention : Quel est le résultat obtenu ?
Avant ce processus, le mot souris n’était pas contextualisé. Il pouvait signifier la souris qui mange du fromage autant que la souris d’ordinateur. À la fin de ce processus, sourisO est une nouvelle représentation du mot souris qui contient des parties des embeddings des mots qui l’entourent dans la phrase; en pârticulier ceux qui sont mesuré comme plus similaire.
Le modèle a donc prêté attention à l’entrée de manière sélective en calculant ce qui était le plus pertinent en fonction de la similarité. La représentation finale du mot souris est modifiée pour inclure le contexte dans lequel le mot fromage existe. Ainsi, les couches suivantes du modèle voient un peu du mot fromage lorsqu’elles voient le mot souris. Ainsi, le modèle comprend ce que signifie le mot souris dans ce contexte car il est lié au mot fromage. Donc, le modèle prête attention aux mots qui l’entourent.
Comment calculer l’attention : l’impact des matrices apprises
Jusqu’à présent, nous avons ignoré les matrices MQ, MK et MV, et l’attention que nous avons expliquée n’est pas intelligente. Elle examine des mots similaires lexicalement et mélange leurs embeddings. Mais avec des MQ, MK et MV bien entraînés, le modèle est capable d’apprendre sur quoi porter attention. En d’autres termes, comment créer de meilleures représentations des mots.
Un ensemble de MQ, MK et MV peut conduire à un mécanisme d’attention qui mélange principalement les verbes et les sujets. D’autres valeurs pour ces matrices peuvent se concentrer sur le mélange des noms et des adjectifs.
Comment est-ce possible ? Eh bien, dans les embeddings, le sens est encodé dans des vecteurs, qui sont des directions dans l’espace. Lorsque vous multipliez des vecteurs par une matrice, vous changez la direction de ces vecteurs. Ainsi, nous pourrions avoir une matrice MQ qui regroupe les vecteurs de noms dans une direction, puis avoir une matrice MK qui regroupe les adjectifs dans la même direction. Maintenant que les deux types de mots ont la même direction, ils sont plus similaires, et lorsque nous multiplions finalement QKT par la matrice I, nous mélangeons des noms et des adjectifs au lieu de mélanger des mots lexicalement liés comme nous le faisions auparavant. La dernière matrice MV est là pour une modification finale de la direction des embeddings, mais elle est moins impactante.
Comment calculer l’attention : quelques points finaux
Veuillez noter que, dans un LLM, ce processus est effectué de nombreuses fois en parallèle par couche. Cela signifie que chaque couche dispose de plusieurs systèmes d’attention (également appelés têtes d’attention) qui ont chacun appris différentes matrices MQ, MK, et MV pour produire de nombreuses représentations focalisées différentes du texte d’entrée. Cela signifie que chaque couche produit de nombreuses variations ou contextualisations du texte d’entrée, qui sont ensuite utilisées par les couches suivantes du LLM pour mieux comprendre le texte à travers divers points de vue.
Enfin, pourquoi les noms Query, Key, Value ? Eh bien, pour chaque mot, la requête (query) examinera tous les autres mots (les clés) pour voir lesquels sont similaires. Lorsque nous savons lesquels le sont, cela nous amène à décider quel mélange de valeurs (value) choisir pour l’intégration finale. Pour contexte, ce schéma de dénomination provient du monde des bases de données.
Mécanismes d’Attention Efficaces pour des LLMs Évolutifs
Malgré son succès, le mécanisme d’attention fait face à plusieurs limitations pratiques. Tout d’abord, il peut être extrêmement inefficace car l’attention standard s’échelonne de manière quadratique avec la longueur de la séquence, entraînant des coûts prohibitifs pour les entrées longues. De plus, les grands modèles de langage nécessitent une mémoire étendue pour stocker les matrices de poids d’attention, ce qui peut limiter la longueur du contexte. Ainsi, bien que nous ayons vu l’attention de base jusqu’à présent, il existe de nombreuses variations de cette technique qui conduisent à de meilleures performances. En voici quelques une :
FlashAttention : Optimisation de la mémoire
Une direction consiste à conserver les calculs d’attention exacts tout en optimisant leur exécution. FlashAttention, par exemple, réorganise la procédure d’attention standard en blocs adaptés à la mémoire afin de réduire les transferts de données coûteux entre la mémoire et les unités de calcul. En traitant les entrées dans ces segments efficaces, FlashAttention fournit les mêmes résultats que l’attention conventionnelle mais avec beaucoup moins de mouvements de mémoire et des temps d’exécution plus rapides.

Linformer & Performer : C’est correct d’approximer
D’autres approches acceptent une petite erreur d’approximation en échange d’une complexité computationnelle beaucoup plus faible. Linformer profite de l’observation que la matrice de similarité complète se situe souvent près d’un sous-espace de faible rang ; elle se compresse facilement. Donc, il projette les clés et les valeurs dans une dimension beaucoup plus petite, réduisant ainsi considérablement la complexité et le temps de calcul. De même, Performer remplace le noyau softmax par une carte de caractéristiques aléatoire, permettant de calculer les poids d’attention en temps linéaire sans perdre les garanties de précision théorique qui sous-tendent les architectures de transformateur.

Longformer & BigBird : prêter attention à tout est un oxymore
Une famille différente de méthodes introduit la parcimonie dans le schéma d’attention au lieu d’une attention globale. Longformer limite l’attention de chaque token (sous-partie de mots) à une fenêtre locale autour de lui, complétée par une poignée de tokens globaux qui peuvent prêter attention à toutes les positions ou être pris en compte par celles-ci. BigBird étend cette idée en connectant aléatoirement des tokens à travers la séquence, garantissant que le contexte global est toujours capturé sans le coût complet de la matrice de similarité. Les modèles construits sur ces schémas parcimonieux peuvent traiter confortablement des documents contenant des millions de tokens, trouvant un équilibre entre la granularité des interactions locales et la cohésion du contexte global.

Reformer : Nous pouvons être plus intelligents concernant l’attention localisée
Reformer adopte une autre approche en regroupant les tokens ayant un contenu similaire grâce au hachage sensible à la localité (LSH). En rassemblant les tokens dans des compartiments basés sur la similarité et en ne calculant l’attention par paires qu’à l’intérieur de chaque compartiment, Reformer accélère considérablement le calcul.
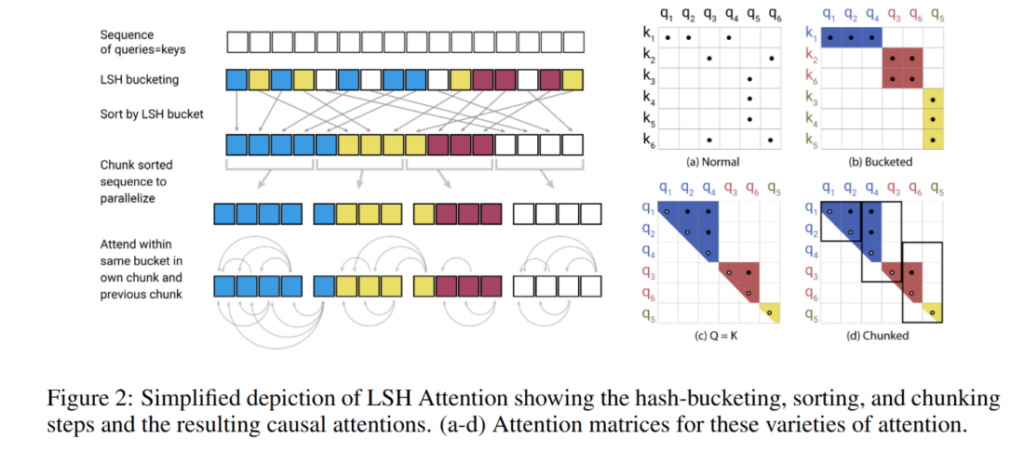
Et il y a encore plus !
Au-delà de ces techniques phares, plusieurs autres variantes s’attaquent à des goulots d’étranglement spécifiques. L’Attention Multi‐Query partage les clés et les valeurs entre les têtes d’attention, réduisant considérablement l’utilisation de la mémoire lors de l’inférence. Le Nyströmformer approche l’attention complète par un échantillonnage astucieux de la matrice d’attention, tandis que les Sparse Transformers adoptent des motifs fixes ou appris de parcimonie pour élaguer les interactions inutiles.

Lors du choix parmi ces mécanismes d’attention efficaces, les praticiens doivent évaluer l’importance de préserver la fidélité exacte du modèle par rapport aux avantages de la réduction des calculs et de la mémoire. FlashAttention et d’autres algorithmes exacts mais optimisés offrent des remplacements directs qui maintiennent une précision complète, tandis que des méthodes approximatives comme Linformer ou Performer offrent des accélérations considérables au prix de légères déviations dans les poids d’attention. Les transformateurs basés sur la parcimonie et le hachage sont idéalement adaptés aux tâches impliquant des entrées très longues, mais ils nécessitent souvent des modifications plus importantes de l’architecture du modèle ou de la procédure d’entraînement. En fin de compte, le meilleur choix dépend de l’application cible, que la priorité soit le traitement de séquences extrêmement longues, la minimisation de la latence d’inférence ou la maximisation de l’efficacité de la mémoire.
Conclusion
Depuis son apparition dans les premiers modèles séquence-à-séquence jusqu’à son rôle central dans la révolution des Transformers, le mécanisme d’attention a fondamentalement transformé le traitement du langage naturel. En permettant aux modèles de se concentrer de manière dynamique sur les informations pertinentes, l’attention a amélioré la traduction automatique et la compréhension du langage, ouvrant la voie aux modèles de langage modernes (LLM). Alors que les chercheurs continuent d’innover en abordant l’efficacité, l’évolutivité et l’interprétabilité, l’attention reste au cœur de la quête de l’IA pour comprendre et générer le langage humain.

En tant que chercheur/développeur indépendant en IA, spécialisé dans le traitement du langage naturel (NLP), j'ai une expertise approfondie dans le développement et l'intégration de systèmes d'IA, ainsi que dans l'analyse de données.
Votre entreprise cherche-t-elle à intégrer des solutions d'IA, à analyser des données ou à renforcer son développement back-end ? Contactez-moi !
Mail : pro.judicael.poumay@gmail.com
Linkedin : Judicaël Poumay
Portfolio : www.judicael-poumay.be