Introduction
Les grands modèles de langage (LLMs) ne perçoivent pas le texte comme une série de caractères ou de mots ; ils utilisent plutôt des tokens. Les tokens sont les atomes du langage que les LLM utilisent pour comprendre et générer du texte. Au fil des années, la tokenisation a évolué, passant des mots aux sous-parties de mots et, plus récemment, aux concepts. Dans cet article, nous explorons pourquoi la tokenisation est si cruciale, passons en revue les premières tentatives, puis plongeons dans les méthodes plus intelligentes qui alimentent les modèles d’aujourd’hui.
Pourquoi les LLM utilisent des tokens et non des mots ?
Les LLMs ne peuvent pas comprendre les lettres et les mots comme nous le faisons ; ce sont des systèmes mathématiques qui fonctionnent sur un ordinateur. Par conséquent, pour traiter du texte, nous devons transformer les mots en une représentation numérique compréhensible pour eux. C’est ce qu’on appelle l’embedding de mots, une idée fondamentale derrière les LLMs. Lorsque nous effectuons un embedding du texte, nous traduisons le langage dans un espace mathématique que les LLMs peuvent comprendre. Imaginez transformer chaque mot en une liste de nombres. Nous n’aborderons pas les embeddings ici, mais vous pouvez en savoir plus à leur sujet dans cet article.
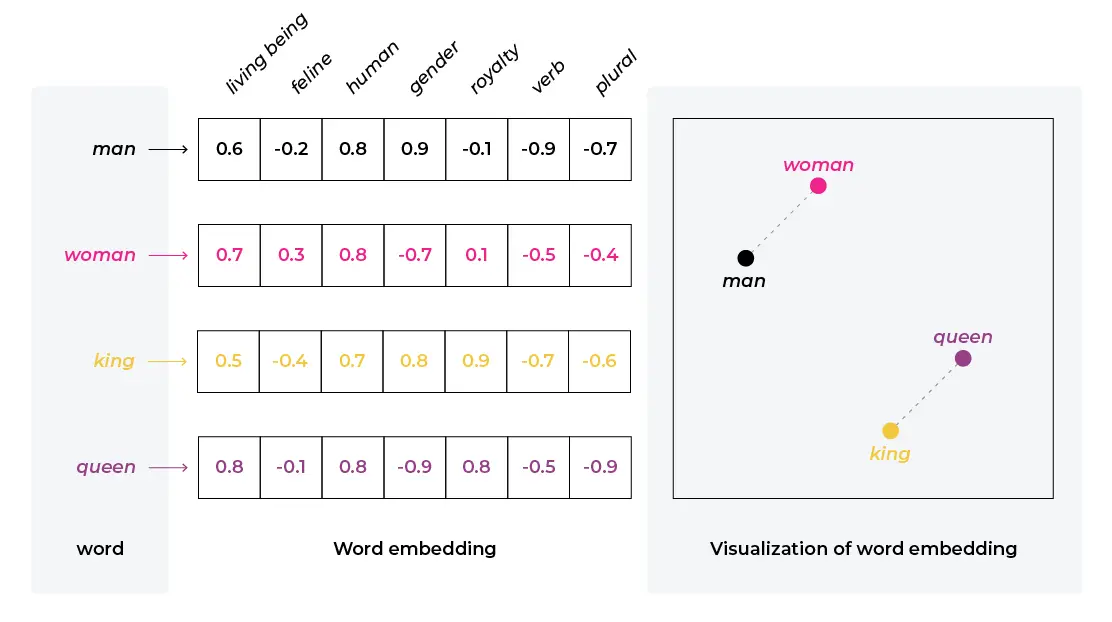
Les premiers systèmes d’embedding, avant l’apparition des LLMs modernes, considéraient les mots comme l’unité atomique du langage. Word2Vec fut l’un des premiers modèles d’embedding de mots. Les embeddings qu’il produisait pouvaient ensuite être utilisés comme entrée pour d’autres modèles afin de générer du texte, bien que très maladroitement à l’époque. C’est pourquoi il était principalement utilisé pour des tâches de classification.
Cependant, cette approche présentait plusieurs limites. Tout d’abord, elle ne pouvait pas gérer efficacement les mots inconnus, car chaque mot du vocabulaire nécessitait un vecteur unique. Si un nouveau mot apparaissait et n’avait pas été vu pendant l’entraînement, le modèle n’avait aucune représentation pour lui. En d’autres termes, si le modèle n’avait jamais rencontré un mot, il ne savait pas quoi en faire. Cela s’appliquait également aux mots mal orthographiés, même avec une seule lettre d’erreur. Ainsi, ces modèles manquaient de flexibilité.
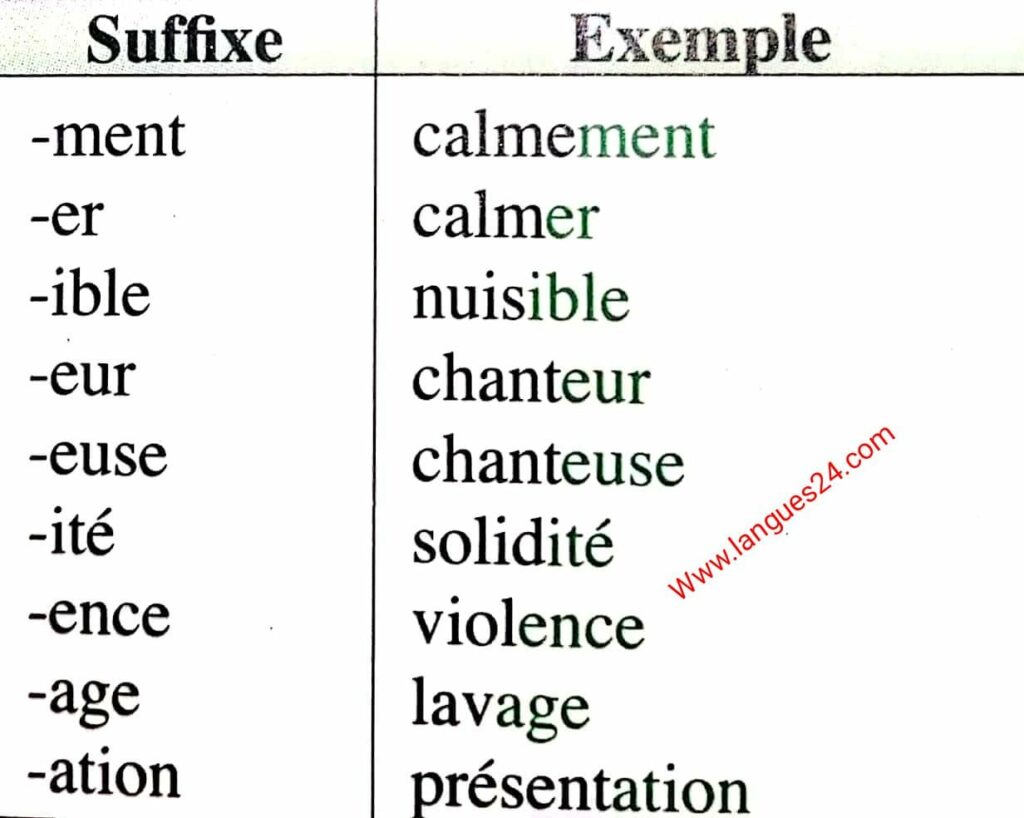
Deuxièmement, dans les langues à morphologie riche, les mots peuvent être composés de plusieurs parties. Par exemple, en francais, calme et calmement sont des variations du mot calmer. Or, comme Word2Vec considérait les mots comme des unités atomiques, il n’était pas capable de modéliser cet aspect du langage. Nous avons donc rapidement compris que les mots n’étaient pas la bonne unité linguistique et qu’il existait une meilleure façon de représenter le texte.
Les tokens avant les LLM : sous-parties de mots et symboles
FastText
L’une des premières améliorations majeures est venue avec FastText, qui représente les mots comme des collections de n-grammes de caractères. Par exemple, malheureusement peut être décomposé en sous-parties comme mal, heureu et sement. Cette approche permet au modèle d’inférer le sens à partir des parties d’un mot, ce qui l’aide à généraliser à de nouveaux mots ou à des mots mal orthographiés.
En effet, si le modèle rencontre un mot inédit comme « malheureusement », il peut reconnaître les sous-parties « mal-« , « -heureu- » et « -sement ». Il en conclurait alors que « malheureusement » exprime le contraire de « heureusement ». Ainsi, les premiers tokens sont nés : des unités linguistiques plus petites que les mots.
Cependant… je vous ai menti. FastText n’était pas assez intelligent pour découper les mots de cette manière. À la place, il traitait « heureusement » de façon plus naïve, en générant des fragments comme « <he", « heu », « eur », « ure », « reu », « use », « sem », « eme », « men », « ent », « nt> » Par conséquent, la méthode créait de nombreux tokens inutiles. Malgré cela, c’était un pas dans la bonne direction, car FastText produisait de meilleurs résultats que Word2Vec.

Embedding des Symboles
Une approche encore plus fine consiste à traiter chaque caractère comme un token. Avec l’embedding au niveau des symboles, chaque lettre, signe de ponctuation et espace devient un token. Cette méthode garantit qu’aucun mot n’est véritablement « inconnu », puisque chaque symboles fait partie du vocabulaire et que chaque mot est composé de l’ensemble de ses caractères. Cela produit des embeddings puissants, mais ignore totalement la sémantique.
L’un des avantages de l’embedding de caractères est qu’il gère très bien les fautes d’orthographe. C’est pourquoi il est souvent utilisé en complément d’autres méthodes, comme FastText. Pour la même raison, il présente un inconvénient majeur : l’embedding de caractères représente de manière similaire des mots ayant des caractères proches. Par exemple, les mots « dock » et « duck » ne diffèrent que par un seul caractère. Pourtant, ils obtiendraient des embeddings similaires.
Ainsi, pendant un certain temps, la combinaison d’embeddings de caractères et de sous-mots représentait l’état de l’art. Elle a révolutionné le domaine du traitement du langage naturel (NLP) et, à terme, le besoin d’un meilleur embedding a conduit à la révolution des modèles de langage de grande taille (LLM). Cependant, à cette époque, les performances des modèles de génération de texte restaient faibles.
LLM : L’essor d’une tokenisation plus intelligente
Les LLM modernes utilisent généralement des techniques intelligentes de tokenisation en sous-mots, qui trouvent un équilibre entre les approches basées sur les mots entiers et celles au niveau des caractères. Ces techniques permettent de gérer dynamiquement la taille du vocabulaire et la longueur des séquences. Une solution est devenue la norme pour de nombreux LLM aujourd’hui : le Byte-Pair Encoding.
Le Byte-Pair Encoding (BPE) est la méthode la plus populaire, utilisée par GPT, Gemini, Claude et la plupart des LLM modernes. BPE a été popularisé par Sennrich et al. (2016) comme un moyen d’équilibrer la taille du vocabulaire tout en produisant des tokens ayant une signification sémantique.
BPE commence par considérer les caractères individuels, puis fusionne itérativement les paires adjacentes les plus fréquentes pour former de nouveaux tokens. Par exemple, prenons le mot « lowering » : il pourrait d’abord être découpé en (l, o, w, e, r, i, n, g). Si « er » est fréquent dans le corpus, BPE le fusionne en un seul token. Ce processus se poursuit de manière itérative jusqu’à obtenir des tokens comme [« low », « er », « ing »]. Cette approche gourmande, basée sur la fréquence, permet de générer efficacement des tokens pertinents, même si les découpages ne correspondent pas toujours parfaitement aux morphèmes naturels.
Tokenisation : solution émergente et alternative
À mesure que les LLM évoluent, les chercheurs continuent d’explorer des alternatives qui vont au-delà des méthodes traditionnelles de tokenisation en sous-mots.
La tokenisation au niveau des octets fonctionne sur les octets bruts plutôt que sur les caractères ou les unités linguistiques. Cette approche commence par encoder le texte en UTF-8, puis applique le BPE aux séquences d’octets résultantes. L’avantage est évident : tous les caractères possibles (y compris les emojis) sont pris en charge, éliminant ainsi les problèmes de vocabulaire hors corpus (out of vocabulary). Cela offre une approche véritablement universelle, fonctionnant à travers les langues et les systèmes de symboles.
La tokenisation morphologique vise à aligner les tokens sur les morphèmes naturels d’une langue (racines, préfixes, suffixes). Par exemple, « misunderstanding » pourrait être segmenté en [« mis », « understand », « ing »], reflétant directement sa structure morphémique. Bien que cette approche soit plus informée linguistiquement et particulièrement efficace pour les langues morphologiquement riches, elle nécessite une connaissance spécifique de chaque langue et peut être plus difficile à généraliser que les méthodes statistiques.
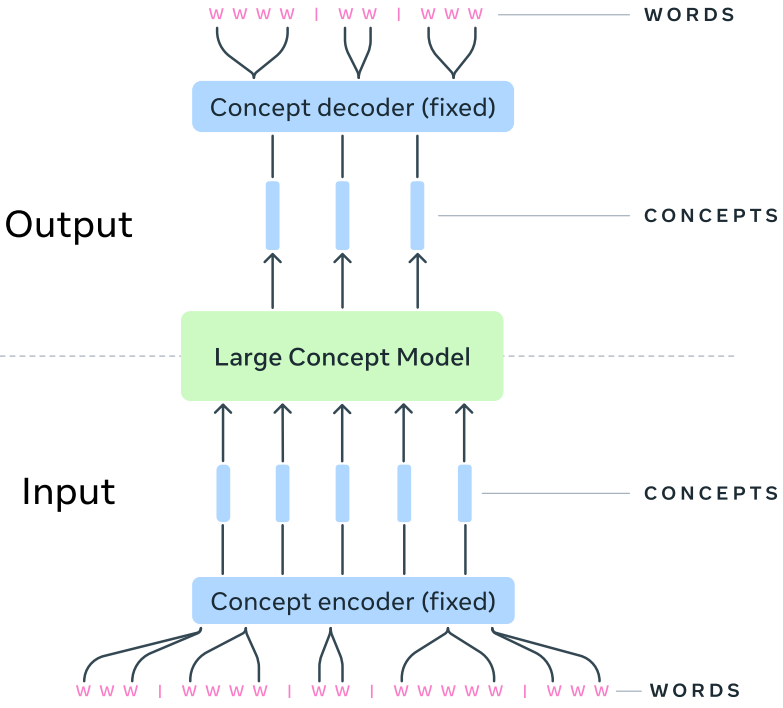
Au-delà des tokens : Les Large Concepts Models
Les Large Concept Models (LCMs) représentent une nouvelle approche de l’IA générative, en se concentrant sur le niveau des concepts, c’est-à-dire des phrases ou des ensembles de phrases plutôt que des tokens individuels. Les LCM génèrent des embeddings pour les sous-mots et, sur cette base, construisent des représentations de phrases entières à l’aide d’un mécanisme d’agrégation sophistiqué, semblable aux couches de pooling des CNN.
Cette représentation basée sur les concepts offre plusieurs avantages : 1) Le modèle capture mieux le sens sémantique global et le contexte général. 2) Cette abstraction améliore l’alignement interlinguistique et l’intégration multimodale, en associant des phrases sémantiquement similaires à des points proches dans l’espace d’embedding, quelle que soit la langue ou le mode (texte, image, etc.). 3) Le traitement au niveau des phrases réduit la taille du modèle et donc son coût. Cette efficacité est particulièrement avantageuse pour gérer de longs documents et des tâches de raisonnement complexes. 4) Enfin, cela améliore la cohérence et la continuité du texte généré, en permettant au modèle de planifier et structurer le contenu à un niveau conceptuel plus élevé, plutôt que de l’assembler à partir de tokens individuels.

En tant que chercheur/développeur indépendant en IA, spécialisé dans le traitement du langage naturel (NLP), j'ai une expertise approfondie dans le développement et l'intégration de systèmes d'IA, ainsi que dans l'analyse de données.
Votre entreprise cherche-t-elle à intégrer des solutions d'IA, à analyser des données ou à renforcer son développement back-end ? Contactez-moi !
Mail : pro.judicael.poumay@gmail.com
Linkedin : Judicaël Poumay
Portfolio : www.judicael-poumay.be