Comment les LLMs stockent l’information? La Superposition des Charactérisques (Expliqué Simplement)

Demandez à ChatGPT des informations sur la physique quantique, l’histoire médiévale ou la cuisine, et il fournit des réponses précises, même hors ligne. Comment sait-il autant de choses ? Le secret réside dans la superposition des caractéristiques , un mécanisme qui permet à l’IA de compresser d’immenses connaissances dans un espace limité. Cette analyse approfondie explore comment l’IA stocke le savoir grâce à cette propriété fascinante.
Fondations : Démêler les caractéristiques des dimensions
Pour comprendre comment l’IA stocke les connaissances, nous devons d’abord distinguer les dimensions des caractéristiques, puis remettre en question l’hypothèse selon laquelle il existe une correspondance un à un entre elles.
Dimensions et caractéristiques
Les dimensions définissent l’espace mathématique où existent les points de données, comme notre monde en 3D avec la longueur, la largeur et la hauteur. Dans les réseaux de neurones, chaque couche contient des neurones qui produisent des valeurs à partir des entrées. La sortie d’un seul neurone peut être considérée comme une dimension d’un vecteur. Ensemble, tous les neurones d’une couche créent un espace n-dimensionnel appelé espace latent. Avec des milliers de neurones par couche, on obtient des espaces de dimensions très élevées.
Les caractéristiques , en revanche, sont des attributs spécifiques et significatifs au sein de cet espace dimensionnel. En science des données, les caractéristiques peuvent représenter des éléments concrets comme l’âge ou la taille. Mais dans les réseaux de neurones, on parle généralement de caractéristiques latentes : des motifs cachés qui ne sont pas directement observables, comme le ton émotionnel d’une phrase ou le style artistique d’une image. Les réseaux de neurones excellent à découvrir ces caractéristiques cachées par eux-mêmes.
L’analogie du code génétique : Démêler les traits des gènes
Idéalement, nous supposerions une correspondance un-à-un entre les caractéristiques et les dimensions. En effet, cela rend les choses plus compréhensibles pour les humains ; l’âge est un nombre, la taille en est un autre. C’est ici que commence l’étrange univers des réseaux neuronaux, et une analogie biologique peut aider.
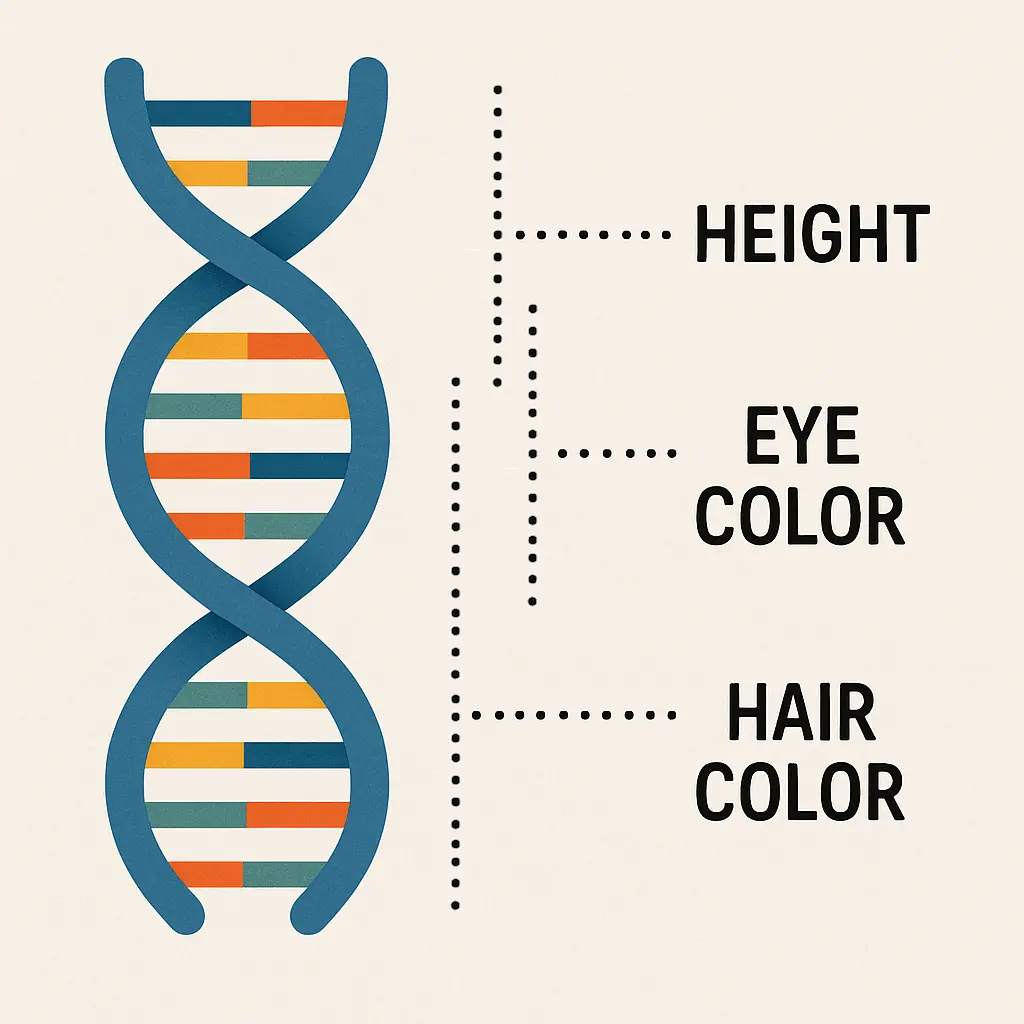
Pensez à la façon dont l’ADN stocke les instructions d’un être vivant. Nous avons autrefois imaginé un modèle simple de « un gène pour un caractère » : un gène pour la couleur des yeux, un pour la taille, un pour la couleur des cheveux. C’est la méthode évidente de stockage des données : une dimension pour une caractéristique. C’est clair, simple à comprendre, mais complètement faux. Notre ADN ne fonctionne pas ainsi ; c’est parce que l’ADN n’a pas été créé par la nature pour être compris.
La réalité est qu’un seul trait, comme la couleur de vos yeux, n’est pas contrôlé par un seul gène. Il est déterminé par un schéma complexe d’interactions entre des centaines ou des milliers de gènes. La couleur des yeux est définie par de nombreux gènes. Chacun d’eux définit également partiellement d’autres traits.
C’est pourquoi certaines maladies génétiques sont liées à la couleur des yeux et à d’autres traits, même si cela ne semble avoir aucun rapport. Ainsi, les traits sont dissociés des gènes individuels. En d’autres termes, les gènes définissent un espace complexe multidimensionnel qui encode de nombreuses caractéristiques. Si les gènes sont des dimensions de cet espace, les caractéristiques n’ont pas besoin de correspondre à des gènes spécifiques et peuvent être partagées entre plusieurs d’entre eux. On dit alors que les caractéristiques sont dissociées des dimensions.
Caractéristiques en tant que directions dans l’espace
Les réseaux neuronaux ont découvert la même stratégie. Un concept n’est pas stocké dans un seul neurone. Il est préférable de comprendre les caractéristiques comme des directions dans l’espace.
Lorsque nous cessons de penser au niveau des dimensions ou des neurones et que nous considérons l’espace latent dans son ensemble, tout devient plus clair. Une caractéristique est un motif d’activation à travers de nombreux neurones. Ces directions sont des encodages de concepts en haute dimension (source). Par exemple, les caractéristiques de « bonheur » et de « rire » pourraient pointer dans des directions très similaires, ce qui indique qu’elles sont sémantiquement liées.
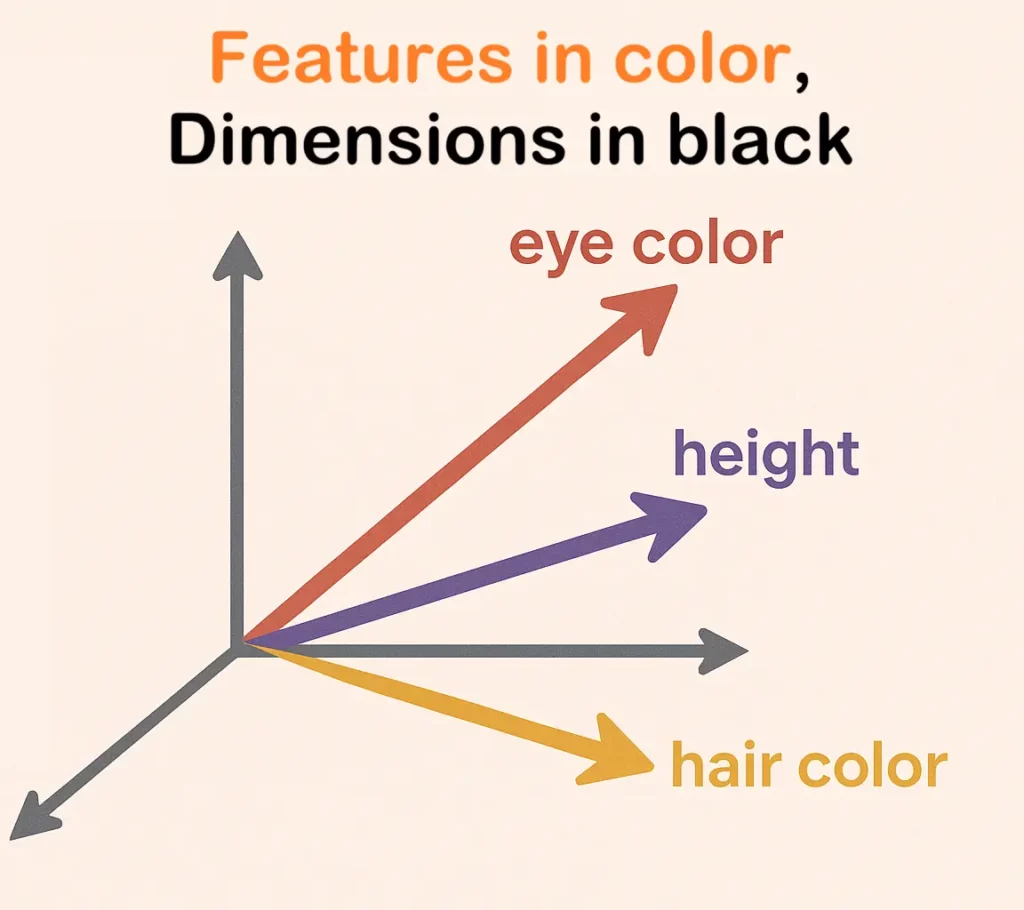
Cette perspective géométrique est cruciale. La multiplication de matrices entre les couches d’un réseau de neurones permet essentiellement de faire pivoter, d’agrandir et de transformer ces vecteurs de caractéristiques, ce qui permet au réseau de construire des représentations de plus en plus complexes à partir d’éléments plus simples. Distinguer les caractéristiques des dimensions est la première étape pour exploiter l’immense capacité de stockage des réseaux de neurones.
En effet, puisque les caractéristiques n’ont pas besoin de s’aligner avec les dimensions, les caractéristiques corrélées peuvent se regrouper dans des directions similaires. Ainsi, nous pouvons encoder plus de caractéristiques que de dimensions, car beaucoup d’entre elles sont en quelque sorte corrélées. Mais que se passe-t-il lorsque le nombre de caractéristiques devient vraiment énorme ?
Qu’est-ce que la superposition ?
Lorsque les réseaux de neurones ont bien plus de caractéristiques à apprendre que de dimensions disponibles (neurones), ils utilisent une solution plus avancée et puissante : la superposition. Cette technique permet aux réseaux de stocker un grand nombre de caractéristiques non liées dans le même ensemble de dimensions en relâchant stratégiquement les règles de séparation géométrique.
Au-delà de l’orthogonalité
Dans un système idéal à grande capacité, chaque caractéristique totalement indépendante se verrait attribuer sa propre direction orthogonale. Vous pouvez les imaginer comme des vecteurs formant des angles parfaits de 90 degrés entre eux, ce qui les rend complètement indépendants. Par exemple, votre âge n’a pas d’incidence sur votre genre. Ainsi, ces deux caractéristiques devraient être encodées dans des directions orthogonales ; l’une peut changer sans affecter l’autre. Un espace à 1024 dimensions ne peut accueillir que 1024 directions parfaitement orthogonales de ce type. Ce serait la limite pour des caractéristiques parfaitement séparées.
La superposition brise cette règle rigide. Au lieu d’exiger une orthogonalité parfaite, elle permet au réseau de représenter des caractéristiques non liées par des directions quasi-orthogonales. Ces directions ne sont pas parfaitement perpendiculaires, mais elles sont extrêmement proches de 90 degrés l’une de l’autre. Cela permet au réseau de stocker beaucoup plus de caractéristiques non liées dans le même espace tout en minimisant l’interférence entre elles. (source)
Le pouvoir contre-intuitif de l’espace de haute dimension
Notre intuition, ancrée dans l’espace 2D et 3D, nous fait complètement défaut en haute dimension. Dans un espace de grande dimension, la géométrie devient à la fois étrange et puissante. Alors qu’un espace de dimension d ne peut contenir que d vecteurs parfaitement orthogonaux, il peut en accueillir un nombre exponentiellement plus grand de vecteurs presque orthogonaux.
Cela crée un immense « espace » pour les caractéristiques. Les réseaux neuronaux en profitent en intégrant des milliers, voire des millions de caractéristiques non liées dans le même espace. Chaque paire peut présenter une légère corrélation et cela engendre des interférence. Celles-ci sont souvent négligeable et les couches ultérieures peuvent souvent les filtrer mais pas parfaitement.
Par interférence, nous entendons que la mesure d’une caractéristique affecte les autres et crée du bruit. Par exemple, si les caractéristiques pour « nom » et « verbe » ne sont pas parfaitement orthogonales, lorsque le modèle identifie un mot comme un verbe, il pourrait aussi penser, très légèrement et à tort, qu’il s’agit d’un nom. Dans des espaces de très haute dimension, cette interférence est minimale. (source)
L’analogie du code génétique, partie 2 : superposition et pléiotropie
Revenons à notre analogie avec l’ADN. Nous avons établi qu’un trait provient de nombreux gènes. Mais la biologie a une autre astuce : un seul gène accomplit souvent différentes fonctions selon l’endroit où il est utilisé, un concept appelé pléiotropie. Un gène qui affecte votre métabolisme peut aussi influencer votre cycle de sommeil et votre densité osseuse. Ces traits (métabolisme, sommeil et densité osseuse) sont en grande partie sans rapport. C’est la superposition des caractéristiques dans un système biologique.
Bien que les gènes soient identiques, l’information contextuelle liée au fait d’être dans différents types de cellules permet au gène de s’exprimer de différentes manières. Ainsi, les mêmes caractéristiques partagent le même gène, et nous avons la superposition.
L’interférence est le compromis biologique : une variante génétique qui vous donne des muscles plus forts peut aussi faire en sorte que vos articulations s’usent plus rapidement. La nature, à travers l’évolution, trouve une combinaison de gènes qui minimise ces interférences négatives, tout comme un réseau de neurones ajuste ses poids lors de l’entraînement pour rendre ses caractéristiques aussi distinctes et exemptes de bruit que possible. Le processus et le résultat sont étonnamment similaires.
Sparsité des caractéristiques : une autre clé de la superposition
Ainsi, la quasi-orthogonalité n’est pas le seul atout. Les réseaux de neurones exploitent également la rareté des caractéristiques. La plupart des caractéristiques ne sont pas pertinentes en même temps.
Imaginez un modèle de vision. Lorsqu’il observe une image de maison, les caractéristiques liées au « toit », à la « porte » et à la « fenêtre » seront activées. Les caractéristiques liées aux « bactéries », au « marché boursier » ou aux « sonnets » resteront inactives. Puisque ces ensembles de caractéristiques sont rarement actifs en même temps, le réseau peut sans risque les regrouper dans les mêmes dimensions, même s’ils sont totalement indépendants. Il apprend qu’une direction particulière peut signifier des choses différentes selon le contexte fourni par les autres caractéristiques actives. (source)
Comment la superposition survient-elle ?
Il est crucial de comprendre que la superposition n’a pas été conçue par l’homme. Il s’agit d’une propriété émergente qui apparaît naturellement lors de l’entraînement de grands réseaux neuronaux sous pression. Le système a découvert cette astuce mathématique de lui-même, car c’est la manière la plus efficace de stocker l’information lorsque les caractéristiques sont plus nombreuses que les neurones.
Des recherches menées par des laboratoires de sécurité de l’IA comme Anthropic, dans leurs expériences intitulées « Modèles jouets de superposition« , montrent que :
- C’est une réponse à la pression : Lorsqu’un modèle dispose d’assez de neurones, il représente les caractéristiques de manière claire. Mais lorsque le nombre de caractéristiques dépasse celui des neurones, le modèle passe brusquement dans un régime de superposition. Cela se produit souvent sous la forme d’une transition de phase nette, comme l’eau qui gèle en glace.
- La parcimonie est un facteur clé : La superposition fonctionne au mieux lorsque les caractéristiques sont parcellaires. Comme seules quelques caractéristiques sont actives pour une entrée donnée, le réseau peut regrouper de nombreuses caractéristiques non superposées dans des dimensions partagées sans conflit.
- Les caractéristiques forment des structures géométriques :**** Les caractéristiques ne sont pas disposées au hasard. Elles s’organisent en formes géométriques élégantes comme des triangles et des tétraèdres dans l’espace de haute dimension, ce qui suggère un ordre profond et caché dans les connaissances du réseau.
La superposition devient l’astuce ultime du réseau pour une efficacité représentationnelle massive, échangeant une séparation nette contre une capacité de stockage exponentielle.
Quelles sont les conséquences de la superposition ?
L’explosion de la capacité (et une pointe d’interférence)
Le gain est énorme : la superposition augmente de façon spectaculaire la capacité d’un modèle. Les LLM peuvent stocker d’immenses quantités de connaissances et de compétences dans leurs paramètres finis. Ce phénomène a été nommé la « loi de Chinchilla », qui constate que les modèles peuvent exploiter efficacement des données d’entraînement bien plus volumineuses que ce que leur nombre de paramètres laisserait supposer.
Mais il y a un piège : l’interférence. Lorsque des dimensions sont partagées, l’activation d’une fonctionnalité en déclenche également légèrement d’autres, non liées. Le réseau essaie de minimiser ce phénomène, mais ce n’est jamais parfait. Cela peut entraîner des compromis inattendus, où l’amélioration des performances sur une tâche nuit à une autre, révélant ainsi le partage de l’espace neuronal. Cette interférence pourrait également contribuer à expliquer pourquoi les hallucinations sont un problème aussi persistant dans les LLM.
Le neurone polysémantique
La superposition crée la polysémanticité. Un neurone polysémantique est un neurone qui s’active pour plusieurs caractéristiques, souvent totalement indépendantes les unes des autres. Des chercheurs ont découvert un neurone dans un modèle de vision qui réagissait à la fois aux « visages de chats » et aux « images d’horloges » (source). Dans un LLM, un seul neurone peut être impliqué dans la représentation de structures grammaticales, de sujets financiers et de noms communs aléatoires.
Si la superposition est la cause (le modèle regroupant des caractéristiques non liées en raison d’une capacité limitée), la polysémanticité est l’effet que nous observons dans les neurones individuels. Cependant, l’inverse n’est pas toujours vrai ; observer la polysémanticité ne signifie pas nécessairement que la superposition en est la seule cause, car elle peut également résulter d’autres dynamiques d’entraînement (source).
Le défi de l’interprétabilité
La polysémanticité détruit le rêve le plus simple de l’interprétabilité de l’IA : jeter un œil à l’intérieur d’un modèle et attribuer un concept clair et lisible par l’humain à chaque neurone (« voici le neurone ‘chat’ »).
La superposition nous oblige à accepter que les véritables unités de sens ne sont pas les neurones ; ce sont des directions dans un espace d’activation de haute dimension. Un concept unique peut émerger d’un motif d’activations réparti sur des milliers de neurones, dont chacun gère simultanément des milliers d’autres concepts. Tenter de comprendre le modèle en examinant un neurone à la fois revient à essayer de comprendre une symphonie en écoutant un seul violoniste.
Une hiérarchie d’importance
La superposition ne traite pas toutes les caractéristiques de manière égale. Les réseaux neuronaux, en minimisant l’erreur, créent un système de tri naturel :
- Caractéristiques les plus importantes : Les fonctionnalités fréquentes et cruciales (comme les règles de grammaire fondamentales dans un LLM) bénéficient de dimensions dédiées, presque orthogonales, pour une précision maximale.
- Fonctionnalités moins importantes : Les fonctionnalités secondaires ou moins fréquentes sont regroupées en superposition, maximisant ainsi l’utilisation de l’espace limité.
- Fonctionnalités les moins importantes : Les fonctionnalités obscures ou rarement utiles peuvent être complètement ignorées.
Cela conduit à une polysémie généralisée parmi les caractéristiques moins cruciales, ce qui peut affecter la fiabilité du modèle dans les cas limites et les sujets de niche.
Sol instable : changements de phase et mémorisation
Les modèles fonctionnant près de leurs limites de capacité peuvent se comporter de manière imprévisible. De petits changements dans les données d’entraînement peuvent déclencher des « transitions de phase » soudaines, où le modèle réorganise de façon spectaculaire ses connaissances internes (source). Cela aide à expliquer des phénomènes comme la double descente, où les performances du modèle chutent de façon surprenante puis remontent après avoir commencé à surajuster.
La superposition est également directement liée à la mémorisation. Lorsqu’un modèle a du mal à apprendre une règle générale, il peut utiliser la superposition pour « tricher » en mémorisant des exemples spécifiques, créant ainsi des caractéristiques hyper-spécifiques pour des points de données individuels au sein de son espace d’activation encombré.
Comment gérons-nous la superposition ?
Comprendre la superposition est essentiel pour développer une intelligence artificielle plus sûre, plus fiable et plus transparente. Les chercheurs explorent deux principales voies à suivre.
Voie 1 : Encourager l’interprétabilité
Cette approche utilise des techniques visant à encourager les modèles à apprendre des représentations plus interprétables et désentrelacées. Nous pouvons ajouter des contraintes pendant l’entraînement afin de pénaliser la polysémanticité, forçant ainsi les caractéristiques à être plus nettement séparées. Bien que cela puisse réduire la capacité brute d’un modèle, les gains en transparence seraient inestimables dans des domaines à enjeux élevés comme le diagnostic médical. (source, source)
Voie 2 : Adopter la boîte noire
Cette approche accepte la superposition comme une propriété essentielle et puissante, en se concentrant plutôt sur le développement de meilleurs outils pour la décoder. Si le sens réside dans les directions, nous avons besoin de méthodes robustes pour les identifier. Des techniques comme le sparse probing et l’apprentissage de dictionnaires visent à « démêler » les signaux superposés, en identifiant les directions spécifiques dans l’espace d’activation qui correspondent à des concepts compréhensibles par l’humain tels que « honnêteté » ou « syntaxe de code ».
Les futures architectures d’IA pourraient intégrer directement ces mécanismes de décodage, créant ainsi des modèles hyper-efficaces et auto-interprétatifs. C’est, selon moi, la direction à suivre. Nous devons accepter que nous construisons de nouveaux esprits que nous ne comprendrons peut-être pas entièrement. Imposer à l’IA d’être compréhensible pour nous risque simplement d’en limiter le potentiel.
Conclusion
La superposition offre une solution profonde à un problème fondamental de l’IA : comment des modèles finis peuvent stocker une quantité apparemment infinie de connaissances. Plutôt que d’attribuer rigidement une caractéristique par dimension, les réseaux de neurones exploitent la géométrie étrange des espaces de haute dimension pour tisser des réseaux d’information denses et efficaces.
Ce phénomène alimente à la fois la puissance remarquable de l’IA et la profonde difficulté à la comprendre. Il en résulte un modèle à la fois brillant et opaque, capable mais d’une complexité déconcertante. Les connaissances d’une IA ne sont pas stockées comme des entrées dans un dictionnaire, mais comme des motifs dans un hologramme, où chaque élément contient une version compressée de l’ensemble. À mesure que les modèles continuent de croître, la maîtrise de la superposition sera cruciale si nous voulons créer une IA véritablement intelligente et bénéfique.



