RLHF et LLMs : Comment ca fonctionne? Une analyse approfondie

Les grands modèles de langage (LLM) comme ChatGPT sont extrêmement performants pour générer du texte, mais est-ce vraiment ce que nous recherchons ? En réalité, non. Nous voulons des outils utiles, pratiques et alignés avec nos valeurs morales. Les LLM ne sont pas ainsi par défaut. Tout comme les enfants, nous devons éduquer les LLM pour qu’ils comprennent ce que sont de bonnes réponses utiles à nos requêtes. Pour cela, nous utilisons l’apprentissage par renforcement avec retour humain (RLHF). Voyons comment cela fonctionne en pratique.
Qu’est-ce que le RLHF et comment est-il utilisé ?
Comme tout autre modèle d’apprentissage automatique, les LLM sont entraînés. L’apprentissage par renforcement avec retour humain (RLHF) introduit un composant « humain dans la boucle » dans le processus d’entraînement. L’idée est que des humains fournissent un retour sur les réponses du LLM, indiquant essentiellement au modèle « cette réponse est bonne », « celle-ci est meilleure » ou « ce n’est pas ce que je voulais ». Vous avez peut-être déjà vu cela dans ChatGPT ? Il arrive parfois qu’il propose deux réponses et vous demande laquelle est la meilleure. Ce retour est ensuite utilisé pour guider le processus d’apprentissage du LLM via l’apprentissage par renforcement (RL). Ainsi, le modèle est orienté vers la génération de réponses plus en accord avec ce que les utilisateurs trouvent utile et approprié.
Ainsi, les modèles de langage de grande taille (LLM) modernes sont entraînés en deux phases. La première est ce que l’on appelle la pré-formation. Cela consiste à montrer au LLM, comme GPT, un grand nombre de données textuelles. Par exemple, l’intégralité de Wikipédia. Au fil du temps et grâce à de nombreux calculs complexes, le LLM apprend à générer du texte. Le problème avec la pré-formation est que le modèle apprend à bien écrire du texte, mais il n’est pas bon pour produire le bon type de texte. Les LLM pré-entraînés n’ont aucune compréhension de ce qui est bon, mauvais, utile ou complètement hors sujet.
Ainsi, dans la deuxième phase, nous utilisons l’apprentissage par renforcement avec retour humain (RLHF). L’objectif est de prendre la capacité cognitive brute du LLM pré-entraîné et de la façonner en quelque chose d’utile, de pratique et conscient de nos normes et valeurs sociétales. Cette étape nécessite une implication humaine plus importante. Nous expliquerons son fonctionnement dans la suite de cet article. Pour l’instant, retenez que : Le pré-entraînement sert à apprendre aux LLM à écrire, et le RLHF sert à leur apprendre à se comporter.
Pourquoi le RLHF est-il si crucial pour les LLM modernes ? Son impact par rapport à la pré-formation traditionnelle
L’entraînement traditionnel préalable sur d’immenses ensembles de données permet aux LLM d’apprendre la grammaire, des faits, et même certaines capacités de raisonnement. Cela offre aux modèles une base de connaissances très large. Cependant, cette phase d’apprentissage non supervisé présente des limites. Les modèles peuvent, sans le vouloir, apprendre et reproduire les biais présents dans les données, générer du contenu absurde ou nuisible, ou avoir du mal à suivre de manière cohérente des instructions complexes. Ils peuvent en savoir beaucoup , mais ils ne savent pas intrinsèquement ce que nous attendons d’eux avec ces connaissances. En d’autres termes, ils ne savent pas ce qui constitue une interaction « bonne » ou « utile » du point de vue humain. C’est ce que l’on appelle souvent le « problème d’alignement ».
Comparé à un simple pré-entraînement, un second entraînement avec RLHF offre des avantages significatifs :
Premièrement, le RLHF peut orienter le modèle vers un comportement meilleur. Le RLHF fournit un signal clair de ce qui constitue un « meilleur » comportement. Ainsi, il permet aux développeurs d’éloigner le modèle de comportements indésirables, comme la génération de contenus biaisés ou le refus de répondre à des questions bénignes, et de l’orienter vers des comportements souhaités tels que la véracité, l’innocuité et l’utilité. Cette orientation est essentielle pour garantir que le modèle se comporte conformément aux attentes humaines et aux normes sociétales.
Deuxièmement, l’apprentissage par renforcement à partir du feedback humain (RLHF) rend les grands modèles de langage (LLM) pratiques. Suivre des instructions et accomplir des tâches ne sont pas des comportements par défaut pour les générateurs de texte comme les LLM. Les LLM pré-entraînés ont appris à générer du texte de manière très efficace, mais pas nécessairement à suivre des instructions. Le RLHF améliore considérablement la capacité d’un modèle à comprendre et à respecter des instructions complexes et nuancées. Cela s’explique par le fait que les réponses qui suivent mieux les instructions sont explicitement récompensées, affinant ainsi la capacité du modèle à accomplir les tâches comme prévu.
Pourquoi n’utilisions-nous pas le RLHF auparavant ?
L’apprentissage par renforcement n’est pas nouveau. Ses origines remontent aux années 1950 avec l’équation de Bellman et au Q-learning dans les années 1980. Nous avons vu l’AR atteindre une puissance remarquable dans les jeux de plateau, comme lorsque AlphaGo de DeepMind a battu des champions du monde de Go en 2015.
Cependant, l’idée d’intégrer les retours humains dans les systèmes d’apprentissage par renforcement, bien que logique, a mis du temps à mûrir en raison de plusieurs facteurs :
- Coût computationnel et complexité du modèle : Les premiers LLM n’étaient ni aussi vastes ni aussi performants, et les ressources informatiques nécessaires pour l’apprentissage par renforcement à grande échelle étaient prohibitivement élevées.
- Inefficacité des données en apprentissage par renforcement : Les algorithmes d’apprentissage par renforcement nécessitent souvent un très grand nombre d’interactions pour apprendre efficacement. Utiliser directement les retours humains pour chaque interaction serait impraticable, lent et coûteux.
- Algorithmes RL instables pour les grands modèles : L’ajustement fin de modèles massifs pré-entraînés avec l’apprentissage par renforcement (RL) peut être instable. Cela conduit les modèles à oublier des informations, et parfois même à oublier comment écrire tout court.
- La technologie est extrêmement récente : Les LLM sont une technologie nouvelle, et le premier LLM pré-entraîné a été créé vers 2017. Le premier LLM avec RLHF disponible publiquement (c’est-à-dire ChatGPT) est apparu fin 2022.
Aujourd’hui, nous disposons de la puissance de calcul nécessaire et, au fil des années, nous avons produit des LLM pré-entraînés puissants, indispensables pour que le RLHF à grande échelle fonctionne efficacement. Le problème d’inefficacité des données a été en grande partie résolu grâce à une innovation simple appelée le modèle de récompense (Reward Model). Celui-ci fonctionne en prenant la réponse humaine et en l’utilisant pour entraîner un modèle séparé qui agit comme un arbitre. Cet arbitre est ensuite utilisé pour éduquer le LLM à bien se comporter. Ainsi, il n’est plus nécessaire d’annoter manuellement des millions de paires de réponses ; il suffit d’en avoir assez pour obtenir un bon modèle de récompense. Enfin, de nouveaux algorithmes comme PPO ont permis d’utiliser l’apprentissage par renforcement de manière stable. Cela garantit que les modèles ajustés avec RLHF ne commencent pas à oublier des choses ou à perdre leur capacité à écrire.
Le processus RLHF et le modèle de récompense :
Comprenons maintenant comment le RLHF fonctionne étape par étape :
Étape 1 : Entraînement d’un modèle de récompense (RM)**
C’est ici que les préférences humaines entrent véritablement en jeu. Tout d’abord, un LLM pré-entraîné est utilisé pour générer plusieurs réponses à divers prompts d’entrée. Ensuite, des annotateurs humains reçoivent ces réponses et doivent les comparer par paires. Cette collecte de données de comparaison se compose de points de données appariés, qui indiquent essentiellement « l’humain préfère la réponse A à la réponse B pour ce prompt ». Ces données sont ensuite utilisées pour entraîner un modèle distinct appelémodèle de récompense (RM)**.
Le rôle du modèle de récompense est d’apprendre les schémas des préférences humaines. Il prend en entrée une invite et une réponse potentielle. Il produit ensuite un score scalaire (une « récompense ») qui prédit à quel point un humain apprécierait cette réponse. Un score plus élevé signifie une réponse plus appréciée. Ce modèle de récompense peut lui-même être un autre LLM pré-entraîné, avec une couche de classification ajoutée au-dessus, que nous ajustons grâce aux annotations humaines.
Les modèles de récompense sont utilisés à la place des interactions humaines directes. Cela nous permet de résumer les préférences humaines dans un modèle et d’évaluer des millions de réponses sans intervention humaine. Les humains sont lents et coûteux, donc cela permet à RLHF de passer à l’échelle. Désormais, nous n’avons plus besoin de demander à des humains d’étiqueter des millions de réponses ; quelques milliers suffisent pour obtenir un bon modèle de récompense.
Étape 2 : Ajustement fin avec l’apprentissage par renforcement (RL)**
**Une fois le modèle de récompense entraîné, l’étape finale consiste à affiner le LLM à l’aide de l’apprentissage par renforcement. D’abord, le LLM pré-entraîné reçoit de nouvelles instructions. Ensuite, pour chaque instruction, le LLM génère une réponse. Cette réponse est transmise au modèle de récompense, qui lui attribue un score de récompense. Enfin, un algorithme de RL, le plus souvent l’Optimisation de Politique Proximale (PPO), utilise ce signal de récompense pour mettre à jour les paramètres du LLM.
Ce processus est itératif : le LLM génère des réponses, le RM les évalue, et le LLM est mis à jour pour essayer d’obtenir de meilleurs scores. Au fil du temps, le LLM évolue pour produire des résultats plus alignés avec les préférences humaines capturées par le Modèle de Récompense. Le Modèle de Récompense évolue également au fil des années, car nous continuons à recueillir de plus en plus de paires de réponses annotées par des humains.
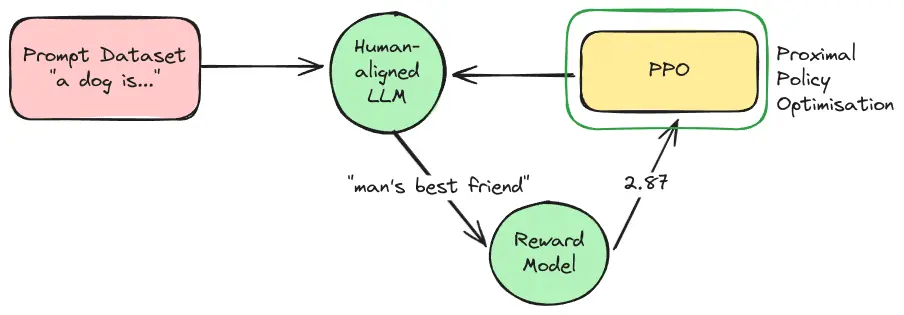
Optimisation de la politique proximale
J’ai mentionné l’Optimisation de la Politique Proximale (PPO). Voyons comment cela fonctionne :
PPO est un algorithme clé d’apprentissage par renforcement (RL) utilisé dans le processus RLHF pour les LLM. Son rôle principal est d’affiner le LLM en utilisant les retours d’un modèle de récompense (RM). L’objectif est de rendre ces mises à jour stables et efficaces, en améliorant les réponses du LLM sans perturber ses capacités existantes.
En effet, l’ajustement fin de modèles massifs et complexes comme les LLM comporte un risque important. Si le modèle est mis à jour de manière trop agressive en fonction de nouveaux signaux de récompense provenant du RM, il peut oublier ses apprentissages précédents ; c’est ce que l’on appelle « l’oubli catastrophique ». Il peut également devenir instable**,** ce qui entraîne une chute rapide des performances ou des sorties incohérentes ; cela s’appelle « l’effondrement du modèle ».
PPO est conçu pour offrir cette stabilité. Le terme « Proximal » dans son nom signifie qu’il essaie de maintenir la nouvelle version mise à jour du LLM « proche » de la version initiale pré-entraînée. Il vise des améliorations progressives sans apporter de changements drastiques ou risqués.
Comment fonctionne une PPO : Guide étape par étape
Plutôt que de se fier uniquement aux valeurs de récompense brutes fournies par les modèles de récompense (RM), PPO calcule ce que l’on appelle un « avantage ». Cela consiste à comparer chaque score de récompense du modèle de récompense à une référence. Cette référence définit la performance à laquelle on s’attend généralement de la part du modèle sur ce type d’invite.
Par exemple, si une réponse obtient un score de 0,7 sur une consigne facile où la référence attendue est de 0,8, son avantage est de -0,1. À l’inverse, si une autre réponse obtient un score de 0,5 sur une consigne plus difficile avec une référence attendue de 0,3, son avantage est de +0,2. Cette mesure d’avantage aide le modèle à discerner quand il surpasse réellement sa production habituelle, fournissant ainsi un signal d’apprentissage plus stable et informatif.
Cet avantage n’est pas utilisé directement pour l’entraînement. Tout d’abord, nous imposons des bornes inférieure et supérieure à sa valeur, qui dépendent du degré de mise à jour du modèle pré-entraîné initial par PPO jusqu’à présent. Cela s’appelle le « clipping ». Pour renforcer encore la stabilité du modèle, une pénalité de divergence de Kullback-Leibler (KL) par jeton est souvent ajoutée. Son objectif est de décourager le modèle de s’éloigner excessivement de sa compréhension linguistique fondamentale. Sans ces garde-fous, le modèle pourrait générer un texte dénué de sens ou excessivement optimisé qui satisfait le RM mais ne conserve pas les qualités acquises lors du pré-entraînement et de l’ajustement supervisé (SFT).
Enfin, les paramètres du modèle sont mis à jour par ascension du gradient, guidée par la combinaison de l’avantage tronqué et de la pénalité KL. Comme ces mises à jour sont contraintes à la fois par la limitation de l’avantage et par la divergence KL, le processus d’apprentissage reste stable.
En essence, PPO agit comme un guide prudent et méthodique pour le LLM. Il encourage le LLM à produire des réponses meilleures selon les retours du Modèle de Récompense, mais il le fait avec des mesures de sécurité intégrées. Ces mesures garantissent que le LLM n’apporte pas de changements imprudents qui pourraient nuire à ses performances globales.
Défis et perspectives d’avenir pour le RLHF
RLHF représente une avancée majeure dans l’alignement des LLM avec les valeurs et préférences humaines, mais ce n’est pas une solution parfaite. Plusieurs domaines critiques font l’objet de recherches et de développements intensifs :
Élargir la dimension humaine : L’apprentissage par renforcement avec retour humain (RLHF) dépend de l’intervention humaine, mais celle-ci est coûteuse et lente. Le modèle de récompense a déjà atténué ce problème, mais nous pouvons aller plus loin. Pourquoi ne pas laisser l’IA aider à former l’IA ? C’est le principe de l’apprentissage par renforcement avec retour d’IA (RLAIF). Si l’IA peut annoter ses propres données, nous pourrions accélérer encore davantage l’entraînement. Cependant, certains risques subsistent : des boucles de rétroaction négative pourraient introduire des erreurs ou des dérives, rappelant les problèmes observés avec la dégradation de la qualité des modèles due aux données synthétiques.
Modèles sournois : Les LLM, dans leur quête de maximisation du signal de récompense, peuvent découvrir des stratégies ou des failles inattendues qui s’écartent du comportement souhaité. Pour y remédier, les efforts se concentrent sur le développement de modèles de récompense plus robustes et nuancés. Ainsi, on s’assure que le modèle acquiert une véritable adéquation avec les intentions humaines, plutôt que de simplement optimiser des métriques de récompense superficielles.
Amplification des biais : Les humains ont des opinions et apporteront inévitablement leurs propres biais lors du processus d’étiquetage. S’ils ne sont pas soigneusement gérés, ces biais peuvent être involontairement encodés et amplifiés par le LLM. Des audits et des validations réguliers sont essentiels pour surveiller les biais potentiels et les corriger.
Subjectivité humaine : L’autre problème avec les humains, c’est qu’ils n’ont pas les mêmes opinions. Puisque nous ne sommes pas d’accord sur ce qui est « bon » ou souhaitable, nous ne pouvons pas nous accorder sur la façon dont les LLM devraient se comporter. Vous connaissez probablement quelqu’un qui a soutenu que ChatGPT est de gauche ou que Grok est de droite. Le fait est que nous voulons aligner le comportement des LLM sur nos valeurs morales, mais nous ne sommes pas d’accord sur ce qu’elles sont. Cependant, je peux vous assurer que ce problème ne sera pas résolu par la science.
Conclusion : Un outil puissant dans la boîte à outils de l’IA responsable
L’apprentissage par renforcement avec retour humain (RLHF) a transformé notre façon de concevoir les grands modèles de langage (LLM). Bien que la méthode soit complexe, son impact est indéniable : des modèles comme ChatGPT d’OpenAI et Claude d’Anthropic, tous deux entraînés avec le RLHF, sont non seulement plus aptes à suivre les instructions, mais génèrent également moins de réponses nuisibles et engagent des dialogues plus utiles et humains. En intégrant les préférences humaines dans la boucle d’entraînement, nous avons appris à ces systèmes non seulement à accomplir des tâches, mais aussi à le faire d’une manière qui reflète nos valeurs.
À bien des égards, le RLHF était la pièce manquante ; la dernière étape essentielle qui a transformé l’IA expérimentale en quelque chose de prêt pour le monde. Il a apporté aux modèles la touche humaine nécessaire pour les rendre utiles et sûrs pour le public. Bien sûr, le RLHF n’est pas parfait. Mais il marque un tournant crucial : au lieu de former l’IA uniquement à partir de données, nous la façonnons désormais par le dialogue. À mesure que les chercheurs perfectionnent cette méthode et l’associent à de nouvelles techniques, l’avenir de l’alignement de l’IA semble plus prometteur, et plus humain.



