Large Language Models (LLMs) like ChatGPT are incredibly good at generating text, but is that really what we want? Actually, no. We want useful tools that are practical and aligned with our moral values. LLMs are not like that by default. Just like children, we have to educate LLMs to understand what are good and useful answers to our prompts. In order to do that, we use Reinforcement Learning with Human Feedback (RLHF). Let’s dive into how this works in practice.
What is RLHF, and how is it used?
Just like any other Machine Learning model, LLMs are trained. Reinforcement Learning with Human Feedback (RLHF) introduces a “human-in-the-loop” component to the training process. The idea is that humans provide feedback on the LLM’s responses, essentially telling the model “this response is good,” “this one is better,” or “this is not what I wanted.” You might have seen this yourself when in ChatGPT? It sometimes provides two answers and asks you which is better. This feedback is then used to guide the LLM’s learning process via Reinforcement Learning (RL). Thus, steering it towards generating responses that are more aligned with what users find useful and appropriate.
Hence, modern Large Language Models (LLMs) are trained in two phases. The first is what we call pre-training. This works by showing the LLM, like GPT, a bunch of textual data. For example, the entirety of Wikipedia. Over time and with a lot of complex math, the LLM learns to generate text. The issue with pretraining is that the model learn to become good at writing text, but it isn’t good at producing the right kind of text. Pre-trained LLMs don’t have any understanding of what is good, bad, useful, or completely irrelevant.
Thus, in the second phase, we use Reinforcement Learning with Human Feedback (RLHF). The goal is to take the raw cognitive ability of the pre-trained LLM and shape it into something useful, practical, and aware of our societal norms and values. This step requires more human involvement. We will explain how it works in the rest of this article. For now, understand that: Pre-training is what we do to teach LLMs how to write, and RLHF is what we do to teach them how to behave.
Why is RLHF So Crucial for Modern LLMs? The Impact vs. Traditional Pre-training
Traditional Pre-training on massive datasets allows LLMs to learn grammar, facts, and even some reasoning capabilities. This provides the models with a broad base of knowledge. However, this unsupervised learning phase has its limitations. Models can inadvertently learn and replicate biases present in the data, generate nonsensical or harmful content, or struggle to consistently follow complex instructions. They might know a lot, but they don’t inherently know what we want them to do with that knowledge. In other words, they don’t know what constitutes a “good” or “helpful” interaction from a human perspective. This is often referred to as the “alignment problem.”
Compared to simple pre-training, a second training with RLHF offers significant advantages:
Firstly, RLHF can steer the model towards better behavior. RLHF provides a clear signal for what constitutes “better”. Thus, allowing developers to steer the model away from undesirable behaviors like generating biased content or refusing to answer benign questions, and toward desired ones such as being truthful, harmless, and helpful. This steering is crucial for ensuring that the model behaves in line with human expectations and societal norms.
Secondly, RLHF makes LLM practical. Following instructions and completing tasks are not the default behavior of text generators like LLMs. Pre-trained LLMs have learned to generate text really well, but necessarily not to follow instructions. RLHF significantly improves a model’s ability to understand and adhere to complex, nuanced instructions. This is because responses that follow instructions better are explicitly rewarded, refining the model’s ability to fulfill tasks as intended.
Why didn’t we use RLHF before?
Reinforcement Learning isn’t new. Its roots trace back to the 1950s with the Bellman Equation and Q-learning in the 1980s. We saw RL achieve remarkable power with board games, such as DeepMind’s AlphaGo defeating world champions in Go in 2015.
However, the idea of incorporating human feedback into RL systems, while intuitive, took time to mature due to several factors:
- Computational Cost & Model Complexity: Early LLMs weren’t as vast or capable, and the computational resources required for large-scale RL were prohibitive.
- Data Inefficiency of RL: RL algorithms often require a vast number of interactions to learn effectively. Directly using human feedback for every interaction would be impractical, slow, and expensive.
- Unstable RL Algorithms for Large Models: Fine-tuning massive pre-trained models with RL can be unstable. This leads models to forget information, and sometimes they forget how to write at all.
- The technology is extremely recent: LLMs are a new technology, and the first pre-trained LLM was created around 2017. The first LLM with RLHF publicly available (a.k.a. ChatGPT) came out at the end of 2022.
Today, we have the computing power, and over the years, we have produced powerful pre-trained LLMs necessary for large-scale RLHF to function effectively. The data inefficiency issue has mostly been solved through a simple innovation called the Reward Model. It works by taking the human response and using it to train a separate model to behave like an arbiter. This arbiter is then used to educate the LLM to behave. Hence, we don’t have to manually label millions of paired responses; only enough to get a good Reward Model. Finally, new algorithms like PPO have made it possible to use RL in a stable way. This ensures that models fine-tuned with RLHF don’t start forgetting things or how to write.
The RLHF Process and the Reward Model:
Let’s now understand how RLHF works step by step :
Step 1: Training a Reward Model (RM)
This is where human preferences truly come into play. First, a pre-trained LLM is used to generate multiple responses to various input prompts. Then, human labellers are presented with these responses and are asked to compare them pairwise. This collection of comparison data is made up of paired data points, which essentially says “human prefers response A over response B for this prompt,”. This is then used to train a separate model called a Reward Model (RM).
The reward model’s job is to learn the patterns in human preferences. It takes a prompt and a potential response as input. It then outputs a scalar score (a “reward”) that predicts how much a human would like that response. A higher score means a more preferred response. This reward model can itself be another pre-trained LLM with a classification layer on top that we fine-tune based on the human labels.
Reward models are used instead of direct human interactions. It allows us to boil down human preferences into a model and evaluate millions of answers without human involvement. Humans are slow and expensive, so this allows RLHF to scale. Now, we don’t have to ask humans to label millions of answers; a few thousand can be enough to get a good reward model.
Step 2: Fine-tuning with Reinforcement Learning (RL)
With a trained reward model in hand, the final step is to fine-tune the LLM using reinforcement learning. First, the pre-trained LLM is presented with new prompts. Then, for each prompt, the LLM generates a response. This response is fed into the Reward Model, which assigns it a reward score. Finally, an RL algorithm, most commonly Proximal Policy Optimization (PPO), uses this reward signal to update the LLM’s parameters.
This process is iterative: the LLM generates responses, the RM scores them, and the LLM is updated to try and get even better scores. Over time, the LLM shifts to produce outputs more aligned with the human preferences captured by the Reward Model. The Reward Model also keeps evolving over the years as we are continuously gathering more and more human-annotated pairs of responses.
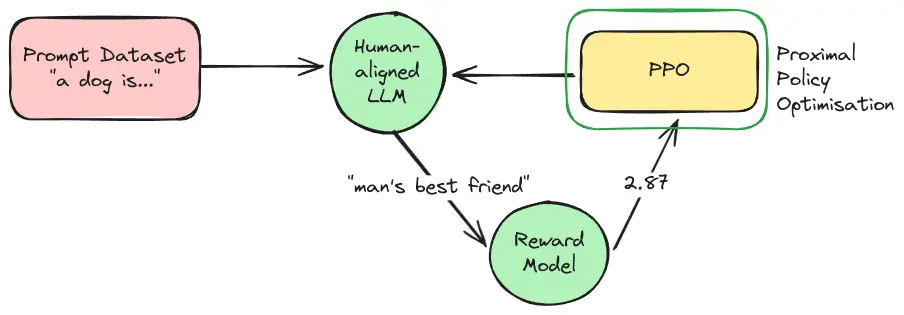
Proximal Policy Optimization
I have mentioned Proximal Policy Optimization (PPO). Let’s see how that works :
PPO is a key RL algorithm used in the RLHF process for LLMs. Its main role is to refine the LLM by using feedback from a Reward Model (RM). The goal is to make these updates stable and efficient, improving the LLM’s responses without disrupting its existing capabilities.
Indeed, fine-tuning massive, complex models like LLMs comes with a significant risk. If the model is updated too aggressively based on new reward signals from the RM, it can forget previous learning; this is known as “catastrophic forgetting.” It can also become unstable, leading to a rapid drop in performance or nonsensical outputs; this is called “model collapse”.
PPO is designed to provide this stability. The “Proximal” in its name means it tries to keep the new, updated version of the LLM “close” to the initial pre-trained version. It aims for steady improvements without making drastic, risky changes.
How PPO Works: A Step-by-Step Guide
Rather than relying on raw reward values provided by the reward models (RM) alone, PPO calculates what we call an “advantage”. This involves comparing each reward score from the reward model to a baseline. This baseline defines how we expect the model to typically perform on that kind of prompt.
For instance, if a response scores 0.7 on an easy prompt where the expected baseline is 0.8, its advantage is -0.1. Conversely, if another response scores 0.5 on a more challenging prompt with an expected baseline of 0.3, its advantage is +0.2. This advantage metric helps the model discern when it is truly outperforming its usual output. Thus, providing a more stable and informative learning signal.
This advantage is not directly used for training. First, we put lower and higher bounds on its value, which depend on how much PPO has updated the initial pre-trained model so far. This is called clipping. To further safeguard the model’s stability, a per-token Kullback-Leibler (KL) divergence penalty is often included. Its purpose is to discourage the model from veering too far from its foundational language understanding. Without these checks, the model might generate nonsensical or overly optimized text that satisfies the RM but fails to retain the qualities instilled during pre-training and supervised fine-tuning (SFT).
Finally, the model’s parameters are updated through gradient ascent, guided by the combination of the clipped advantage and the KL penalty. Because these updates are constrained by both bounding the advantage and the KL divergence, the learning process remains stable.
In essence, PPO acts as a careful and methodical guide for the LLM. It encourages the LLM to produce responses that are better according to the Reward Model’s feedback, but it does so with built-in safety measures. These measures ensure the LLM doesn’t make reckless changes that could harm its overall performance.
Challenges and the Road Ahead for RLHF
RLHF represents a pivotal development in aligning LLMs with human values and preferences, but it is not a perfect solution. Several critical areas are under intense research and development :
Scaling the Human Touch: RLHF depends on human input, but people are expensive and slow. The Reward Model already alleviated this problem, but we can do better. Why not let AI help teach AI? This is the idea behind Reinforcement Learning from AI Feedback (RLAIF). If AI can label its data, we could accelerate training even more. Although some risks remain: Negative feedback loops could introduce errors or drift, echoing problems we’ve seen with synthetic data degrading model quality.
Sneaky models: LLMs, in their pursuit of maximizing the reward signal, may discover unintended strategies or loopholes that deviate from desired behavior. To mitigate this, efforts are focused on developing more robust and nuanced reward models. Thus, ensuring the model learns genuine alignment with human intentions rather than merely optimizing for superficial reward metrics.
Bias amplification: Humans have opinions and will inevitably bring their own biases to the labeling process. If not carefully managed, these biases can be inadvertently encoded and amplified by the LLM. Ongoing audits and validation are essential to monitor for potential biases and correct them.
Human subjectivity: The other problem with humans, they don’t have the same opinions. Since we don’t agree on what is “good” or desirable, we can’t agree on how LLM should behave. You probably know someone who has argued that ChatGPT is left-wing or Grok is right-wing. The point is, we want to align LLM behavior to our moral values, but don’t agree on what they are. However, I can assure you this problem won’t be solved by science.
Conclusion: A Powerful Tool in the Responsible AI Toolkit
Reinforcement Learning with Human Feedback (RLHF) has transformed how we build Large Language Models (LLMs). While the method is complex, its impact is unmistakable: models like OpenAI’s ChatGPT and Anthropic’s Claude, both trained with RLHF, are not only more adept at following instructions but also generate fewer harmful responses and engage in more helpful, humanlike dialogue. By inserting human preferences into the training loop, we taught these systems not just to perform tasks but to do so in ways that reflect our values.
In many ways, RLHF was the missing piece; the last essential step that turned experimental AI into something ready for the world. It gave models the human touch needed to be publicly useful and safe. Of course, RLHF isn’t perfect. But it marks a critical shift: instead of training AI purely on data, we now shape it through dialogue. As researchers refine this method and pair it with emerging techniques, the future of AI alignment looks more promising, and more human.

As an independent AI researcher/developer specialized in Natural Language Processing (NLP), I have a comprehensive expertise in the development and integration of AI systems, as well as data analysis.
Is your company looking to integrate AI solutions, analyze data, or strengthen its back-end development? Contact me!
Mail : pro.judicael.poumay@gmail.com
Linkedin : Judicaël Poumay
Portfolio : www.judicael-poumay.be
- How RLHF works for LLMs : A Deep Dive - 1 July 2025
- Attention Mechanism in LLM Explained : A Deep Dive - 27 May 2025
- Tokenization in LLMs: Why Not Use Words? - 6 March 2025