Large Language Models (LLMs) are now a part of our lives, but how are they so effective? What is the essential element that makes LLM so powerful? The answer is in the title of the most important scientific paper that led to the creation of LLMs: “Attention is all you need” which gave us the modern attention mechanism.

The attention mechanism is one of the most important concepts in current AI systems. Inspired by the human ability to focus selectively on things, attention enables neural networks to prioritize the most relevant information. Hence, AI models can have a much more focused understanding of the problem they are given. In this article, I will try to clarify the complexity behind attention without simplifying too much.
Why is attention so important?
The world is a complex place, much more than we realize. Our human brain has evolved over millions of years to ignore most of the world. Why? Because 1) most things are irrelevant and 2) there is an almost infinite amount of information around you. Hence, your brain has to filter information. Do you remember the color of the floor in your regular supermarket? Probably not. You don’t pay attention to that.
The less you notice irrelevant stuff, the more brain power you can spend on what matters. This incredible ability to decide what is relevant makes us efficient, allowing us to solve complex problems. We have evolved this ability over millions of years of evolution; for us, it is so obvious that we don’t realize it, but for AI, it isn’t.
AI systems don’t pay attention by default. Without attention, ask a basic AI to classify images of cats and birds, what does it see? Everything; it sees every pixel, it notices the color of the floor, and that’s not useful. Thus, AI has to learn where to look and what to filter, but how? In the case of Large Language Models (LLM), which words are the most important to understand and answer a query?
What does it mean for an LLM to pay attention?
Attention in LLM allows each word in a sentence to be weighted according to relevance. Rather than processing every word uniformly, attention dynamically reassigns importance, ensuring that key words and phrases receive more focus.
Let’s give you a practical example. If I ask an LLM :
“Please, GPT, can you tell me what is the most likely pet in a household?”
It will focus on what it thinks is the most important element of the question, in this case “what”, “likely”, “pet”, and “household”. As a response, it will probably talk about cats and dogs. The LLM pays less attention to words like “please” because they are not relevant to the question asked.
The attention mechanism allows LLM to contextualize words to help the model better understand a given problem. Without this, the IA would see each word in a text without understanding how they are linked. For example, verbs are related to subjects. Thus, the attention mechanism can attach the subject to a verb. Then, when the model sees the verb, it won’t simply see one word but will also know which subject is related to it. In other words, now, when the LLM sees the verb it can also pays attention to the subject that is linked to it.
The mathematics behind the attention mechanism
Now that we understand the basic idea, let’s see if we can unpack the math behind the attention mechanism. First, we will need a bit of background.
A note on embeddings
Words are part of the human language, but LLMs are mathematical systems that only understand numbers. Hence, in practice, we need to translate words into mathematical structures for LLM to manipulate them. You can learn more in this article if you are interested.
A quick summary is that words are represented by vectors such that these vectors encode the meaning of words. Now that words are translated into a mathematical space, we can do math with words. For example, KING-MAN+WOMAN=QUEEN is a true formula in this vector space. We call this method word embedding because we embed words into a vector space.
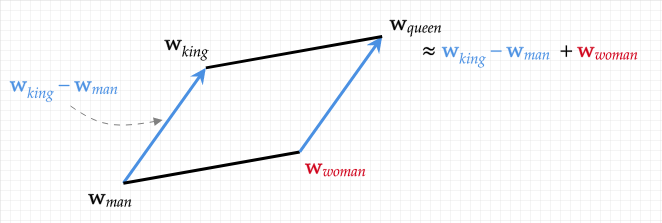
The main idea behind the attention mechanism is to use a basic embedding and produce a more complex one that includes context. For example, in the sentence “I walked by the river bank”, the word bank alone is ambiguous. Hence, we want a way to properly contextualize the word bank such that the model understands that it is the bank of a river and not a financial institution that is referring to. This is what the attention mechanism does.
To do this, we take a general vector representation of the word bank called a static embedding; it encodes the word bank in all of its possible meanings. Then, we try to create a new representation banknew= bank + river, thus creating a new representation that is contextualized. This means that when the model sees the vector representation banknew it will also see part of the representation of the word river and better understand what the word bank means in this context. Thus, it pays attention to the other words to better understand.
A note on similarity
To decide what we should pay attention to, the model needs to measure how related two words are. This can be done by taking the dot product of their embeddings. When you multiply two embeddings/vector elements by element and add the results, you get a single scalar: the dot product. If two word embeddings point in similar directions, their dot product is large otherwise, it is small or negative
In the world of embeddings, pointing in the same direction means having a similar meaning. For example, the embeddings for “cat” and “dog” exist in a similar lexical field; they appear in similar contexts. Hence, their dot product is high. On the other hand, “cat” and “debt” rarely share the same contexts. This produces a much lower score.

Moreover, word embeddings contain a lot more information about words than just meaning. For example, they also encode syntactic information such that, in general, noun-noun pairs dot-products are higher than noun-verb pairs. We can use these properties to produce a powerful attention mechanism.
How to compute attention: a trivial example
Simplified version of the attention formula
The complete attention formula is a bit complex: O=softmax(scale(QKT))V. Let’s simplify some things. Let’s set aside softmax and scaling for now; they won’t help us understand.
Now we must understand the rest of the formula, O = QKTV. The matrices Q, K, and V are defined as such :
- The Query Q = I*MQ
- The key K = I*MK
- The value V = I*MV
The MQ, MK, and MV are also matrices and their values are learned; this is what we do when we train an LLM. We will talk about them later; let’s ignore them for now to understand an even simpler formula. This means we now have O = IITI.
Computing a simplified similarity matrix
Now, the formula is much simpler: O = IITI. What’s going on here? Let’s imagine a basic phrase, for example “walk by river bank”, we produce a sequence of input embeddings I = (i1,…,in) representing a list of vectors (walk, by, river, bank). Thus, the matrix I is defined as a sequence of word embeddings representing the input text.
First in our formula, we multiply I and IT. This means multiplying (walk, by, river, bank) by its transpose. Consequently, this produces a new 4×4 matrix as shown below. As you can see, we are multiplying each word embedding in the matrix I by each other. Remember, this means we compute the similarity between each word as explained above.
| walk*walk | by*walk | river*walk | bank*walk |
| walk*by | by*by | river*by | bank*by |
| walk*river | by*river | river*river | bank*river |
| walk*bank | by*bank | river*bank | bank*bank |
Let’s use fake similarity values to make things simple. For example, bank*bank=1 because they are the same word. bank*river is close to 1 because they are part of the same lexical field. Continuing for each value, we produce a new matrix S equal to IIT, which measures how each word is lexically related to each other. Let’s call the Similarity matrix.
Computing a simplified attention mechanism
Then we can compute the rest of the formula IITI= SI, multiplying S and I. Multiplying S by I creates a new matrix O = SI = (walkO, byO, riverO, bankO). As a result, we produce new embeddings for each word that are a weighted mix of the original input embeddings.
For exemple, bankO is equal to walk*(bank*walk) + by*(bank*by) + bank*(bank*bank) + river*(bank*river). Hence, bankO is a mix of the embedding of all the other words in the input sequence, weighted by their similarity. For example, bankO=walk*0.4 + by*0.2 + river*0.8 + bank*1. Notice that bank*bank=1 since it is the same word, and river*bank=0.8 since they are lexically related. This means this new representation of the word bank also contains part of the representation of the word river. We produced a new embedding that is contextualized.
Computing Attention: What do we get as a result?
Before this process, the word bank was not contextualised. It could have meant the bank of a river as much as the bank where you place your money. At the end of this process, bankO is a new representation of the word bank that contains parts of the embeddings of the words around it in the sentence; in particular, those that are measured as more similar.
The model thus paid attention to the input selectively by computing what was most relevant based on similarity. The final representation of the word bank is modified to include the context in which the word river exists. Hence, the next layers of the model see a bit of the word river when they see the word bank. Thus, the model understands what the word bank means in this context as it is related to the word river. Hence, the model can pay attention to surrounding words.
How to compute attention: the impact of learned matrices
So far, we have ignored the matrix MQ, MK, and MV, and the attention we explained isn’t smart. It looks at lexically similar words and mixes their embeddings. But with well-trained MQ, MK, and MV, the model is capable of learning what to pay attention to. In other words, how to create better word representations.
Some set of MQ, MK, and MV may lead to an attention mechanism that mostly mixes verbs and subjects. Other values for these matrices may focus on mixing nouns and adjectives.
How is that possible? Well, in embeddings, meaning is encoded in vectors, which are directions in space. When you multiply vectors by a matrix, you change the direction of those vectors. Hence, we could have a matrix MQ that groups noun vectors in one direction, then have a matrix MK that groups adjectives in the same direction. Now that both types of words have the same direction, they are more similar, and when we finally multiply QKT by the matrix I, we are mixing nouns and adjectives instead of mixing lexically related words as we did before. The last matrix MV is there for a final modification of the embedding directions, but it is less impactful.
How to compute attention: some final points
Please note that, inside an LLM, this process is done many times in parallel per layer. Meaning that each layer has multiple attention systems (also called attention heads) that have each learned different MQ, MK, and MV matrices to produce many different focused representations of the input text. This means each layer produces many variations or contextualizations of the input text, which are then used by subsequent layers of the LLM to better understand the text through various points of view.
Finally, why the name Query, Key, Value? Well, for each word, the query will look at all the other words (the keys) to see which are similar. When we know which are, this leads us to decide what mix of values to choose for the final embedding. For context, this naming scheme comes from the world of databases.
Efficient Attention Mechanisms for Scalable LLMs
Despite its success, the attention mechanism faces several practical challenges. First, it can be extremely inefficient as standard attention scales quadratically with the sequence length, leading to prohibitive costs for long inputs. Moreover, Large LLMs require extensive memory to store attention weight matrices, which can limit context length. Hence, while we have seen basic attention so far, there exist many variations of this technique that lead to better performance. Here are some of them :
FlashAttention: Optimizing memory
One direction is to retain exact attention computations but optimize their execution. FlashAttention, for example, reorganizes the standard attention procedure into memory‐friendly blocks to reduce costly data transfers between memory and compute units. By processing inputs in these efficient segments, FlashAttention delivers the same outputs as conventional attention but with far fewer memory movements and faster runtimes.

Linformer & Performer: It’s ok to approximate
Other approaches accept a small approximation error in exchange for dramatically lower computational complexity. Linformer takes advantage of the observation that the similarity matrix often lies close to a low‐rank subspace; it is easily compressible. Thus, it projects the keys and values into a much smaller dimension, bringing complexity and thus computation time down considerably. Similarly, Performer replaces the softmax kernel with a randomized feature map, enabling attention weights to be computed in linear time without losing the theoretical accuracy guarantees that underpin transformer architectures.

Longformer & BigBird: paying attention to everything is an oxymoron
A different family of methods introduces sparsity to the attention pattern instead of using a global attention. Longformer confines each token‘s (sub-word elements) attention to a local window around it, supplemented by a handful of global tokens that can attend to, or be attended by, all positions. BigBird extends this idea further by randomly connecting tokens across the sequence, ensuring that global context is still captured without the full similarity matrix cost. Models built on these sparse patterns can comfortably process documents running into the millions of tokens, striking a balance between the granularity of local interactions and the cohesion of global context.

Reformer: We can be smarter about localized attention
Reformer takes yet another tack by grouping tokens with similar content through locality‐sensitive hashing (LSH). By grouping tokens into buckets based on similarity and only computing pairwise attention within each bucket, Reformer speeds up computation significantly.
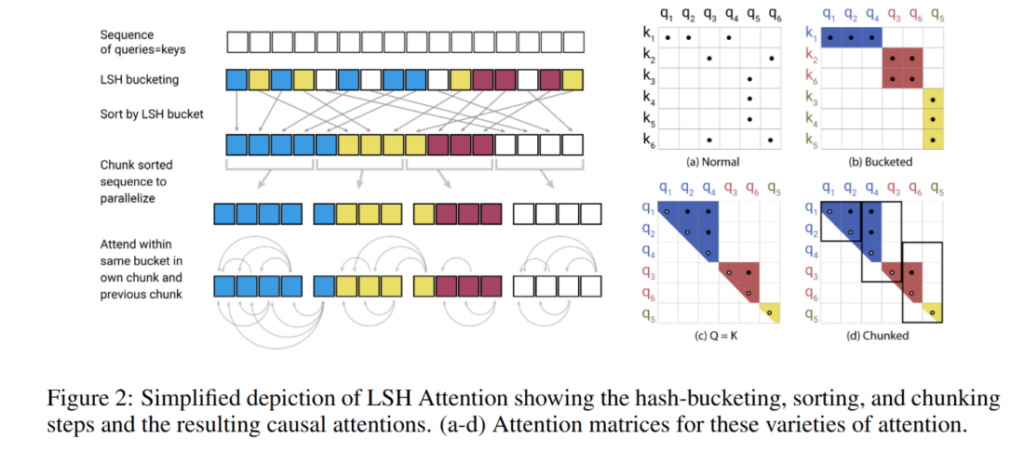
And there is more!
Beyond these headline techniques, several other variants address specific bottlenecks. Multi‐Query Attention shares keys and values across attention heads, cutting down memory usage dramatically during inference. The Nyströmformer approximates full attention through clever sampling of the attention matrix, while Sparse Transformers adopt fixed or learned sparse patterns to prune unnecessary interactions.

When choosing among these efficient attention mechanisms, practitioners must weigh the importance of preserving exact model fidelity against the benefits of reduced compute and memory overhead. FlashAttention and other exact‐but‐optimized algorithms offer drop‐in replacements that maintain full accuracy, whereas approximate methods like Linformer or Performer deliver orders‐of‐magnitude speed‐ups at the cost of slight deviations in the attention weights. Sparse and hashing‐based transformers are ideally suited for tasks involving very long inputs, but they often require more extensive modifications to the model architecture or training procedure. Ultimately, the best choice depends on the target application, whether the priority is processing extreme sequence lengths, minimizing inference latency, or maximizing memory efficiency.
Conclusion
From its inception in early sequence-to-sequence models to its central role in the Transformer revolution, the attention mechanism has fundamentally reshaped natural language processing. By enabling models to focus dynamically on relevant information, attention improved machine translation and language understanding and paved the way for modern LLMs. As researchers continue to innovate, addressing efficiency, scalability, and interpretability, attention remains at the heart of AI’s quest to understand and generate human language.

As an independent AI researcher/developer specialized in Natural Language Processing (NLP), I have a comprehensive expertise in the development and integration of AI systems, as well as data analysis.
Is your company looking to integrate AI solutions, analyze data, or strengthen its back-end development? Contact me!
Mail : pro.judicael.poumay@gmail.com
Linkedin : Judicaël Poumay
Portfolio : www.judicael-poumay.be
- Attention Mechanism in LLM Explained : A Deep Dive - 27 May 2025
- Tokenization in LLMs: Why Not Use Words? - 6 March 2025
- Defining AGI : Why OpenAI’s o3 Isn’t Enough to achieve Artificial General Intelligence - 26 December 2024