Introduction
Large Language Models (LLMs) do not see text as a series of characters or words; instead they use tokens. Tokens are the atoms of language that LLM uses to understand and generate text. Over the years, tokenization has evolved from words to subwords and, more recently, concepts. In this article, we explore why tokenization is so crucial, review early attempts, and then dive into the smarter methods powering today’s models.
Why do LLM use Tokens and not Words?
LLMs cannot understand letters and words, they are mathematical systems which run on a computer. Therefore, in order to process text, we need to transform words into some numerical representation that makes sense for them. This is called word embedding; the fundamental idea behind LLMs. When we embed text, we translate language into a mathematical space that LLMs can understand. Imagine transforming each word into a list of numbers. We will not review embeddings here but you can read more about them in this article.
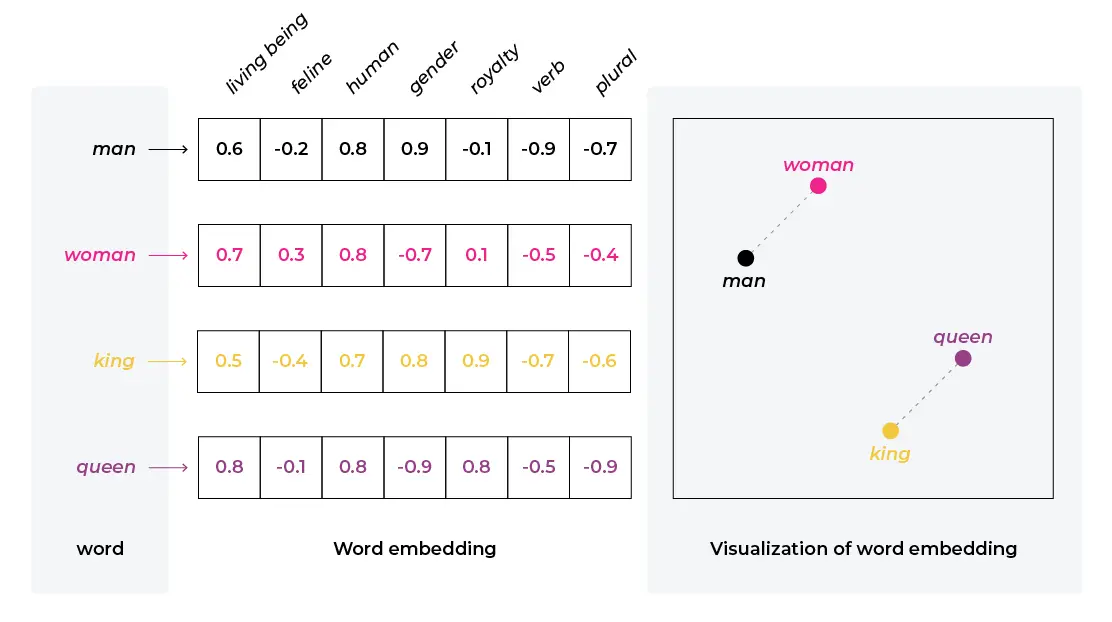
Early embedders, before modern LLMs, considered words as the atomic unit of language. Word2Vec was one of the first word embedders. The embeddings it produced could then be used as input for other models to generate text, although very badly at the time. Hence, it was mostly used for classification tasks.
However, this approach had several limitations. First, it could not handle unseen words effectively, as each word in the vocabulary required a unique vector. If a new word appeared that was not seen during training, the model had no representation for it. In other words, if the model had never seen a word, it had no idea what to do with it. This also applied if the word written was misspelt even by just one letter. Hence, those models were not very flexible.
Second, in languages with rich morphology words may be composed of parts. For example, in English, “running”, and “runner” both are modifications of “run”. Yet, as word2vec assumed that words are atomic units, it was not able to model this part of language. Therefore, we soon realised that words were not the proper unit of language and that there was a better way of representing text.

Tokens before LLM : Subword and Characters
FastText
One of the first major improvements came with FastText, which represents words as collections of character n-grams. For example, “unhappiness” can be decomposed into substrings such as “un,” “happi,” and “ness.” This approach enables the model to infer meaning from parts of a word, helping it generalize to new or misspelled words.
Indeed, if the model sees a new word like “unalive”, it could understand the atoms “un-” and “-alive”. The conclusion would be that “unalive“ means the opposite of alive. Hence, the first tokens were born. Linguistics units that were smaller than words.
However, I’ve lied to you. FastText was not smart enough to split words like “unhappiness” in such a way. Instead, FastText processed “unhappiness” more naively as “”. Therefore, the method created many irrelevant tokens. Nonetheless, it was a step in the right direction as it produced better results than word2vec.

Character Embedding
An even more fine-grained approach treats each character as a token. With character-level embedding, every letter, punctuation mark, and space becomes a token. This method guarantees that no word is truly “unknown” since every character is part of the vocabulary and every word is made up of all of the characters. This produces powerful embeddings but completely ignores semantics.
One advantage of character embedding is that they are really good at handling misspellings. This is why they are often used in tandem with others such as FastText. For the same reason, they have one big problem : character embedding would represent similar words with similar characters. For example, the words “dock” and “duck” have only one character different between them. Yet, they would get similar embeddings.
Therefore, for a while, using a combination of character and sub-word embeddings was the state of the art. It revolutionised the field of NLP and eventually the need for better embedding led to the LLM revolution. However, at the time, the performance of models for text generation remained poor.
LLM : The Rise of Smarter Tokenization
Modern LLMs generally use smart subword tokenization techniques that strike a balance between whole-word and character-level approaches, dynamically managing vocabulary size and sequence length. One solution became the standard used by many LLM today : Byte-Pair Encoding.
Byte-Pair Encoding (BPE) is the most popular method, used by GPT, Gemini, Claude and most modern LLM. BPE was popularized by Sennrich et al. (2016) as a way to balance vocabulary size while producing semantically meaningful tokens.
BPE starts with individual characters and iteratively merges the most frequent adjacent pairs to form new tokens. For example, consider the word “lowering”: it might initially be split into : (l, o, w, e, r, i, n, g). If “er” is frequent in the corpus, BPE merges it into a single token. We keep doing this iteratively and eventually we get tokens like [“low”, “er”, “ing”]. This greedy, frequency-based approach efficiently produces efficient tokens, though it sometimes produces splits that do not perfectly align with natural morphemes.
Emerging and Alternative Tokenization Methods
As LLMs evolve, researchers continue to explore alternatives that push beyond traditional subword methods.
As words are encoded into bytes in our computers, byte-level tokenization operates on raw bytes rather than characters or linguistic units. This approach begins by encoding text in UTF-8 and then applying BPE to the resulting byte sequences. The advantage is clear: every possible character (or even emoji) is covered, effectively eliminating out of vocabulary issues. It offers a truly universal approach that works across languages and symbol systems.
Morphological tokenization seeks to align tokens with natural language morphemes (roots, prefixes, suffixes). For instance, “misunderstanding” could be split into [“mis”, “understand”, “ing”], directly reflecting its morphemic structure. While this approach is more linguistically informed and can be particularly effective for morphologically rich languages, it also requires additional language-specific knowledge and may not scale as easily as statistical methods.
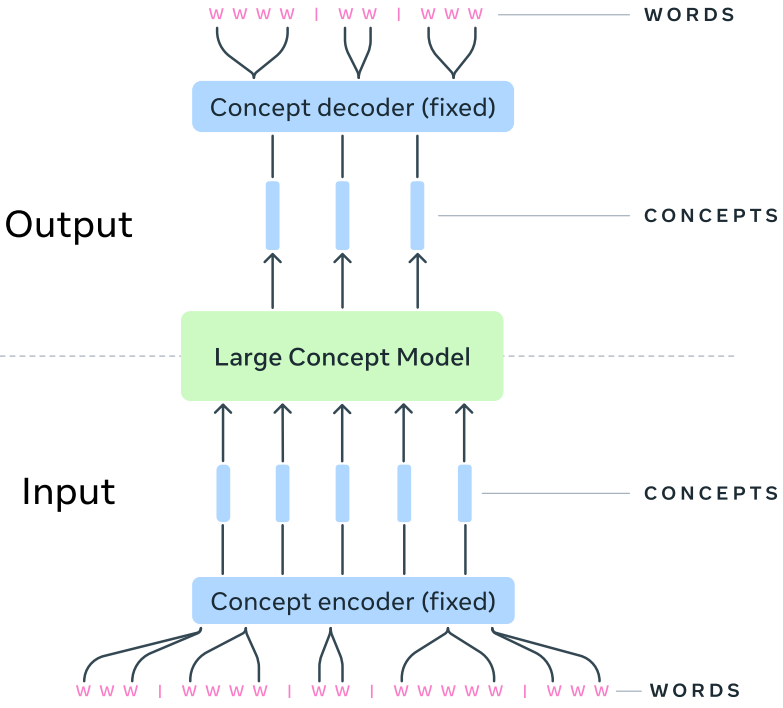
Beyond Tokens: Large Concept Models
Large Concept Models (LCMs) represent a new approach to generative AI, focusing on the level of concepts; i.e. phrases or entire sentences rather than individual tokens. LCMs generate embeddings for sub-word tokens and, based on these, construct representations for entire sentences using a sophisticated averaging mechanism similar to the pooling layers in CNN.
This concept-level representation offers several advantages. 1)The model better captures high-level semantic meaning and global context. 2) This abstraction enhances cross-lingual alignment and multimodal integration, as semantically similar sentences across different languages or modalities are mapped to nearby points in the embedding space. 3) Additionally, processing at the sentence level reduces model size and thus cost. This efficiency is particularly beneficial for handling long documents and complex reasoning tasks. 4) Moreover, it improves text generation coherence and contextual consistency by allowing the model to plan and structure content at a higher conceptual level, rather than assembling it from individual tokens.

As an independent AI researcher/developer specialized in Natural Language Processing (NLP), I have a comprehensive expertise in the development and integration of AI systems, as well as data analysis.
Is your company looking to integrate AI solutions, analyze data, or strengthen its back-end development? Contact me!
Mail : pro.judicael.poumay@gmail.com
Linkedin : Judicaël Poumay
Portfolio : www.judicael-poumay.be
- Python Release History (2026): From 3.0 to 3.15 What Changed? - 15 March 2026
- How to Setup Azure SSO with FastAPI: A Complete Guide - 18 October 2025
- Why is the AI revolution so slow? (It’s not) - 18 September 2025