How Does LLMs Store Knowledge? A Deep Dive Into Feature Superposition

Ask ChatGPT about quantum physics, medieval history, or cooking, and it delivers precise answers, even offline. How does it know so much? The secret is feature superposition , a mechanism allowing AI to compress vast knowledge into a finite space. This deep dive explores how AI stores knowledge using this fascinating property.
The Foundation: Disentangling Features from Dimensions
To understand how AI stores knowledge, we must first distinguish between dimensions and features, and then break the assumption that they have a one-to-one relationship.
Dimensions and Features
Dimensions define the mathematical space where data points exist, like our 3D world with length, width, and height. In neural networks, each layer contains neurons that produce values based on input. A single neuron’s output can be thought of as one dimension of a vector. Together, all neurons in a layer create an n-dimensional space called a latent space. With thousands of neurons per layer, we get correspondingly high-dimensional spaces.
Features , on the other hand, are specific, meaningful attributes within this dimensional space. In data science, features might represent concrete patterns like age or height. But in neural networks, we’re usually talking about latent features ; hidden patterns that aren’t directly observable, like the emotional tone of a sentence or the artistic style of an image. Neural networks excel at discovering these hidden features on their own.
The Genetic Code Analogy: Disentangling Traits from Genes
Ideally, we would assume a one-to-one mapping between features and dimensions. Indeed, this makes things more understandable to humans; age is one number, and height another. This is where the strange world of neural networks begins, and a biological analogy can help.
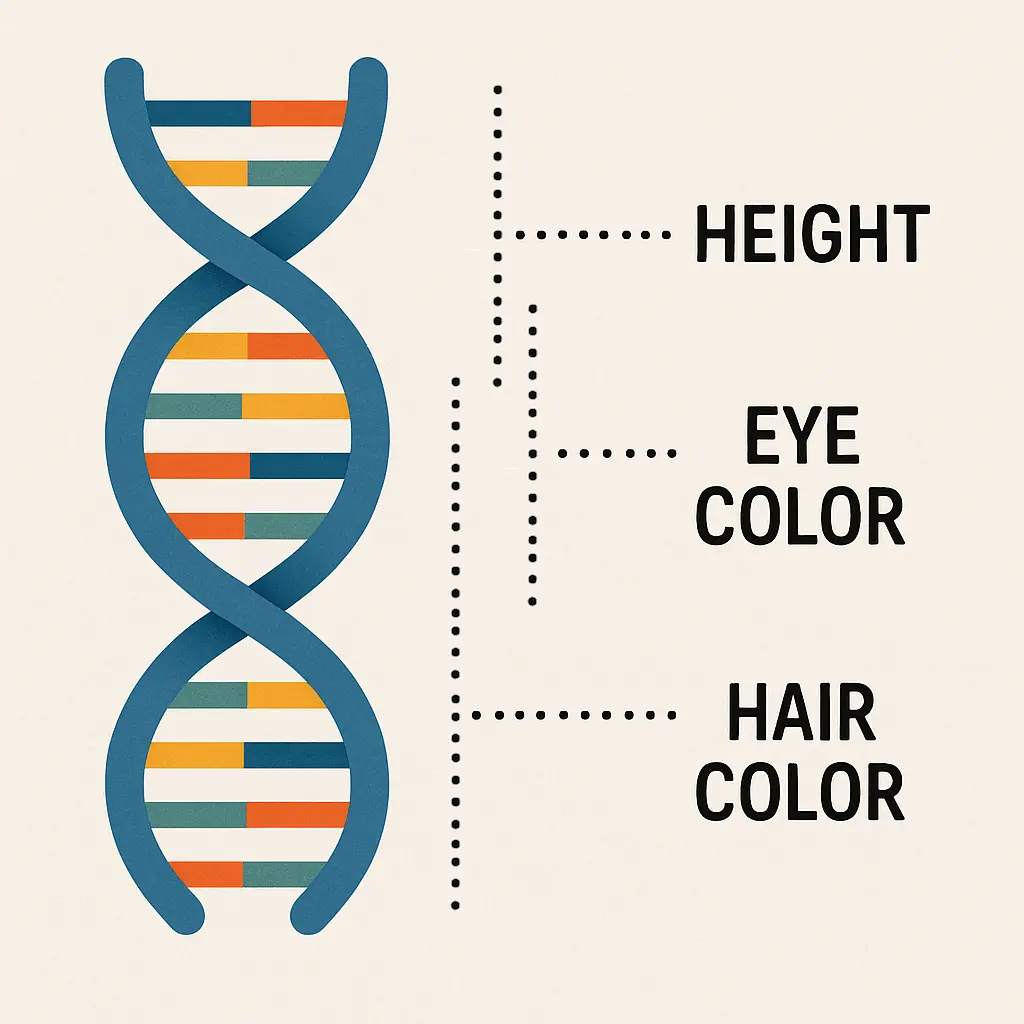
Think about how DNA stores the instructions for a living being. We once imagined a simple “one gene for one trait” model: one gene for eye color, one for height, one for hair color. This is the obvious method of data storage: one dimension for one feature. It’s clean, simple to understand, but completely wrong. Our DNA doesn’t work this way; this is because DNA was not created by nature to be understood.
The reality is that a single trait, like your eye color, isn’t controlled by one gene. It’s determined by a complex pattern of interactions across hundreds or thousands of genes. Eye color is defined by many genes. Each of them also defines other traits partially.
This is why some genetic diseases are related to eye color and other traits, even if they seemingly have nothing to do with that. Thus, traits are disentangled from individual genes. In other words, genes define a complex multi-dimensional space that encodes many features. If genes are dimensions of that space, features do not need to align with specific genes and may be shared across many. We say that features are disentangled from dimensions.
Features as Directions in Space
Neural networks discovered the same strategy. A concept isn’t stored in a single neuron. Instead, it’s best to understand features as directions in space.
When we stop thinking at the dimension/neuron level and look at the latent space as a whole, everything becomes clearer. A feature is a pattern of activation across many neurons. These directions are high-dimensional encodings of concepts (source). For example, the features for “happiness” and “laughter” might point in very similar directions, indicating they are semantically related.
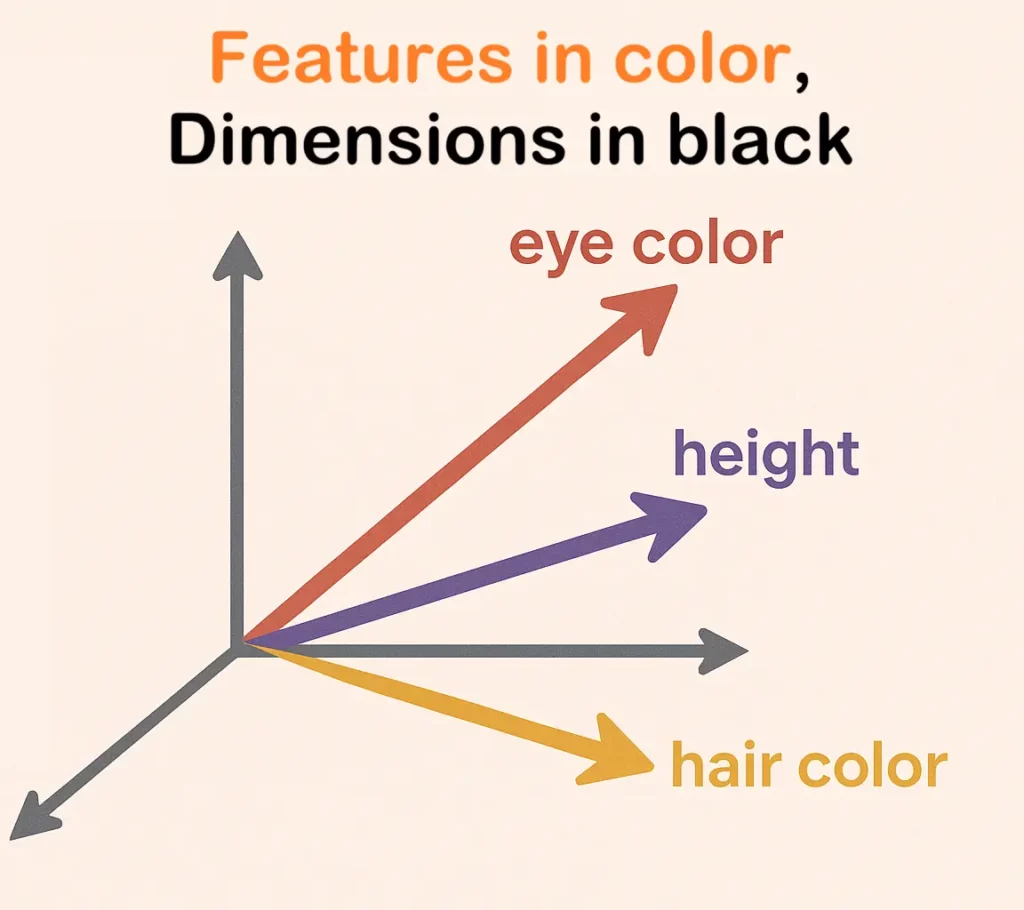
This geometric perspective is crucial. Matrix multiplication between layers in a neural network essentially rotates, scales, and transforms these feature vectors, allowing the network to build up increasingly complex representations from simpler ones. Disentangling features from dimensions is the first step to unlocking the massive storage capacity of neural networks.
Indeed, since features do not need to align with dimensions, correlated features can pack into similar directions. Therefore, we can encode more features than dimensions since many are somewhat correlated. But what happens when the number of features becomes truly enormous?
What is Superposition?
When neural networks have far more features to learn than available dimensions (neurons), they employ a more advanced and powerful solution: superposition. This technique allows networks to store a vast number of unrelated features in the same set of dimensions by strategically relaxing the rules of geometric separation.
Beyond Orthogonality
In an ideal, high-capacity system, each purely unrelated feature would get its own orthogonal direction. You can think of these as vectors sitting at perfect 90-degree angles to each other, making them completely independent. For example, your age does not impact your gender. Thus, both features are expected to be encoded in orthogonal directions; one can change without impacting the other. A 1024-dimensional space can only accommodate 1024 such perfectly orthogonal directions. This would be the limit for cleanly separated features.
Superposition breaks this rigid rule. Instead of demanding perfect orthogonality, it allows the network to represent unrelated features with near-orthogonal directions. These directions aren’t perfectly perpendicular but are extremely close to 90 degrees apart. This allows the network to store many more unrelated features in the same space while keeping the interference between them to a minimum. (source)
The Counter-Intuitive Power of High-Dimensional Space
Our intuition, rooted in 2D and 3D space, completely fails us in high dimensions. In high-dimensional space, geometry becomes both bizarre and powerful. While a d-dimensional space can fit only d perfectly orthogonal vectors, it can accommodate an exponentially larger number of almost orthogonal vectors.
This creates vast “room” for features. Neural networks exploit this by packing thousands or even millions of unrelated features into the same space. Each pair might correlate slightly and this creates interference. This can be filtered out by later layers, but not perfectly.
By interference, we mean that measuring one feature affects others and creates noise. For example, if the features for “noun” and “verb” aren’t perfectly orthogonal, when the model identifies a word as a verb, it might also think very slightly and incorrectly that it’s a noun. In ultra-high-dimensional spaces, this interference is minimal. (source)
The Genetic Code Analogy Part 2: Superposition and Pleiotropy
Let’s return to our DNA analogy. We’ve established that one trait comes from many genes. But biology has another trick: a single gene often does different things depending on where it is used, a concept called pleiotropy. A gene that affects your metabolism might also influence your sleep cycle and bone density. These traits (metabolism, sleep, and bone density) are largely unrelated. This is feature superposition in a biological system.
Even though the genes are the same, the contextual information of being in different types of cells allows the gene to express itself in different ways. Thus, the same features share the same gene, and we have superposition.
Interference is the biological trade-off : A gene variant that gives you stronger muscles might also make your joints wear out faster. Nature, through evolution, finds a combination of genes that minimizes these negative interferences, just as a neural network adjusts its weights during training to make its features as distinct and noise-free as possible. The process and result are surprisingly similar.
Feature Sparsity: Another Key to Superposition
Hence, near orthogonality isn’t the only trick. Neural networks also exploit feature sparsity. Most features are not relevant at the same time.
Imagine a vision model. When it’s looking at an image of a house, features related to “roof,” “door,” and “window” will be active. Features related to “bacteria,” “stock market,” or “sonnets” will be dormant. Since these feature sets are rarely active together, the network can safely pack them into the same dimensions. Even though they are completely unrelated. It learns that a particular direction can mean different things depending on the context provided by other active features. (source)
How does Superposition arise?
It is crucial to understand that superposition wasn’t engineered by humans. It is an emergent property that arises naturally from training large neural networks under pressure. The system discovered this mathematical trick on its own because it’s the most efficient way to store information when features outnumber neurons.
Research from AI safety labs like Anthropic, in their “Toy Models of Superposition” experiments, shows that:
- It’s a Response to Pressure : When a model has enough neurons, it represents features cleanly. But when the number of features exceeds the number of neurons, the model abruptly shifts into a superposition regime. This often occurs as a sharp phase transition , like water freezing into ice.
- Sparsity is a Key Enabler : Superposition works best when features are sparse. Since only a few features are active for any given input, the network can pack many non-overlapping features into shared dimensions without conflict.
- Features Form Geometric Structures :**** The features aren’t packed randomly. They organize themselves into elegant geometric shapes like triangles and tetrahedrons in the high-dimensional space, suggesting a deep, hidden order to the network’s knowledge.
Superposition becomes the network’s ultimate hack for massive representational efficiency, trading clean separation for exponential storage capacity.
What are the Consequences of Superposition?
The Capacity Boom (and a Hint of Interference)
The payoff is enormous: superposition dramatically boosts a model’s capacity. LLMs can store vast knowledge and skills within their finite parameters. This has been coined the “Chinchilla Law”, which observes that models can effectively utilize training data far larger than their parameter count would suggest.
But there’s a catch: interference. When dimensions are shared, activating one feature also slightly triggers unrelated others. The network tries to minimize this, but it’s never perfect. This can create unexpected trade-offs where improving performance on one task hurts another, revealing the shared neural real estate. This interference might also be a contributing factor to why hallucinations are such a persistent problem in LLMs.
The Polysemantic Neuron
Superposition creates polysemanticity. A polysemantic neuron is one that fires for multiple, often completely unrelated, features. Researchers found a neuron in a vision model that responded to both “cat faces” and “pictures of clocks” (source). In an LLM, a single neuron might be involved in representing grammatical structures, finance topics, and random nouns.
If superposition is the cause (the model packing unrelated features due to limited capacity), polysemanticity is the effect we observe in individual neurons. However, the reverse is not always true; observing polysemanticity doesn’t necessarily mean superposition is the only cause, as it can arise from other training dynamics (source).
The Challenge of Interpretability
Polysemanticity destroys the simplest dream of AI interpretability: peeking inside a model and assigning a clear, human-readable concept to each neuron (“this is the ‘cat’ neuron”).
Superposition forces us to accept that the real units of meaning aren’t neurons; they are directions in a high-dimensional activation space. A single concept might emerge from a pattern of activations spread across thousands of neurons, each of which is simultaneously juggling thousands of other concepts. Trying to understand the model by examining one neuron at a time is like trying to understand a symphony by listening to a single violinist.
A Hierarchy of Importance
Superposition doesn’t treat all features equally. Neural networks, in minimizing error, create a natural triage system:
- Most Important Features : Frequent, critical features (like fundamental grammar rules in an LLM) get dedicated, nearly orthogonal dimensions for maximum accuracy.
- Less Important Features : Secondary or less frequent features get packed together in superposition, maximizing the use of limited space.
- Least Important Features : Obscure or rarely useful features might be ignored entirely.
This leads to widespread polysemanticity among less critical features, which can impact model reliability on edge cases and niche topics.
Unstable Ground: Phase Changes and Memorization
Models operating near their capacity limits can behave unpredictably. Small changes in training data can trigger sudden “phase transitions” where the model dramatically reorganizes its internal knowledge (source). This helps explain phenomena like double descent, where model performance surprisingly drops and then rises again after it has begun to overfit.
Superposition also connects directly to memorization. When a model struggles to learn a general rule, it can use superposition to “cheat” by memorizing specific examples, creating hyper-specific features for individual data points within its crowded activation space.
How do we deal with Superposition?
Understanding superposition is crucial for building safer, more reliable, and transparent AI. Researchers are exploring two main paths forward.
Path 1: Encouraging Interpretability
This approach uses techniques to encourage models to learn more interpretable, disentangled representations. We can add constraints during training to penalize polysemanticity, forcing features to be more cleanly separated. While this could reduce a model’s raw capacity, the gains in transparency would be invaluable in high-stakes fields like medical diagnosis. (source, source)
Path 2: Embracing the Black Box
This path accepts superposition as an essential and powerful property, focusing instead on building better tools to decode it. If meaning lies in directions, we need robust methods to find those directions. Techniques like sparse probing and dictionary learning aim to “unmix” superposed signals, identifying the specific directions in activation space that correspond to human-understandable concepts like “honesty” or “code syntax.”
Future AI architectures might incorporate these decoding mechanisms directly, creating hyper-efficient, self-interpreting models. This is where I believe we must go. We have to accept that we’re building new minds that we might not fully understand. Constraining AI to be understood by us may only limit its potential.
Conclusion
Superposition offers a profound solution to a fundamental AI problem: how finite models can store a seemingly infinite amount of knowledge. Rather than rigidly assigning one feature per dimension, neural networks harness the bizarre geometry of high-dimensional spaces to weave dense, efficient webs of information.
This phenomenon drives both AI’s remarkable power and the deep challenge of understanding it. The result is a model that is brilliant yet opaque, capable yet bewilderingly complex. An AI’s knowledge isn’t stored like entries in a dictionary but like patterns in a hologram, where each piece contains a compressed version of the whole. As models continue to grow, mastering superposition will be crucial if we want to create truly intelligent and beneficial AI.



